August 09, 2021
| Tags:
Hyperion,
Volume Rendering,
SIGGRAPH
This year at SIGGRAPH 2021, Wei-Feng Wayne Huang, Peter Kutz, Matt Jen-Yuan Chiang, and I have a talk that presents a pair of new distance-sampling techniques for improving emission and scattering importance sampling for volume path tracing cases where low-order heterogeneous scattering dominates.
These techniques were developed as part of our ongoing development on Disney’s Hyperion Renderer and first saw full-fledged production use on Raya and the Last Dragon, although limited testing of in-progress versions also happened on Frozen 2.
This work was led by Wayne, building upon important groundwork that was put in place by Peter before Peter left Disney Animation.
Matt and I played more of an advisory or consulting role on this project, mostly helping with brainstorming, puzzling through ideas, and figuring out how to formally describe and present these new techniques.
Here is the paper abstract:
We present two new distance-sampling methods for production volume path tracing. We extend the null-collision integral formulation to efficiently gather heterogeneous volumetric emission, achieving higher-quality results. Additionally, we propose a tabulation-based approach to importance sample volumetric in-scattering through a spatial guiding data structure. Our methods improve the sampling efficiency for scenarios where low-order heterogeneous scattering dominates, which tends to cause high variance renderings with existing null-collision methods.
As covered in several previous publications, several years ago we replaced Hyperion’s old residual ratio tracking [Novák et al. 2014 , Fong et al. 2017] based volume rendering system with a new, state of the art, null-collision (also called delta tracking or Woodcock tracking) tracking theory based volume rendering system.
Null-collision volume rendering systems are extremely good at dense volumes where light transport is dominated by high-order scattering, such as clouds and snow and sea foam.
However, null-collision volume rendering systems historically have struggled with efficiently rendering optically thin volumes dominated by low-order scattering, such as mist and fog.
The reason null-collision systems struggle with optically thin volumes is because in a thin volume, the average sampled distance is usually very large, meaning that ray often goes right through the volume with very few scattering events [Villemin et al. 2018].
Since we can only evaluate illumination at each scattering event, not having a lot of scattering events means that the illumination estimate is necessarily often very low-quality, leading to tons of noise.
Frozen 2’s forest scenes tended to include large amounts of atmospheric fog to lend the movie a moody look; these atmospherics proved to be a major challenge for Hyperion’s modern volume rendering system.
Going in to Raya and the Last Dragon, we knew that the challenge was only going to get harder: from fairly early on in Raya and the Last Dragon’s production, we already knew that the cinematography direction for the film was going to rely heavily on atmospherics and fog [Bryant et al. 2021] even more than Frozen 2’s cinematography did.
To make things even harder, we also knew that a lot of these atmospherics were going to be lit using emissive volume light sources like fire or torches; not only did we need a good way to improve how we sampled scattering events, but we also needed a better way to sample emission.
The solution to the second problem (emission sampling) actually came long before the solution to the first problem (scattering sampling).
When we first implemented our new volume rendering system, we evaluated the emission term only when an absorption even happened, which is an intuitive interpretation of a random walk since each interaction is associated with one particular event.
However, shortly after we wrote our Spectral and Decomposition Tracking paper [Kutz et al. 2017], Peter realized that absorption and emission can actually also be evaluated at scattering and null-collision events too, and provided that some care was taken, doing so could be kept unbiased and mathematically correct as well.
Peter implemented this technique in Hyperion before he move on from Disney Animation; later, through experiences from using an early version of this technique on Frozen 2, Wayne realized that the relationship between voxel size and majorant value needed to be factored in to this technique.
When Wayne made the necessary modifications from his realization, the end result sped up this technique dramatically and in some scenes sped up overall volume rendering by up to a factor of 2x.
A complete description of how all of the above is done and how it can be kept unbiased and mathematically correct makes up the first part of our talk.
The solution to the first problem (scattering sampling) came out of many brainstorming and discussion sessions between Wayne, Matt, and myself.
At each volume scattering point, there are three terms that need to be sampled: transmittance, radiance, and the phase function.
The latter two are directly analogous to incoming radiance and the BRDF lobe at a surface scattering event; transmittance is an additional thing that volumes have to worry about over what surfaces care about.
The problem we were facing in optically thin volumes fundamentally boiled down to cases where these three terms have extremely different distributions for the same point in space.
In surface path tracing, the solution to this type of problem is well understood: sample these different distributions using separate techniques and combine using MIS [Villemin & Hery 2013].
However, we had two obstacles preventing us from using MIS here: first, MIS requires knowing a sampling pdf, and at the time, computing the sampling pdf for distance sampling in a null-collision system was an unsolved problem.
Second, we needed a way to do distance sampling based off of not transmittance, but instead the product of incoming radiance and the phase function; this term needed to be learned on-the-fly and stored in an easy-to-sample spatial data structure.
Fortunately, almost exactly around the time we were discussing these problems, Miller et al. [2019] was published, which solved the longstanding open research problem around computing a usable pdf for distance samples, allowing for MIS.
Our idea for on-the-fly learning of the product of incoming radiance and the phase function was to simply piggyback off of Hyperion’s existing cache points light-selection-guiding data structure [Burley et al. 2018].
Wayne worked through the details of all of the above and implemented both in Hyperion, and also figured out how to combine this technique with the previously existing transmittance-based distance sampling and with Peter’s emission sampling technique; the detailed description of this technique makes up the second part of our talk.
The end product is a system that combines different techniques for handling thin and thick volumes to produce good, efficient results in a single unified volume integrator!
Because of the limited length of the SIGGRAPH Talks short paper format, we had to compress our text significantly to fit into the required short paper length.
We put much more detail into the slides that Wayne presented at SIGGRAPH 2021; for anyone that is interested and is attending SIGGRAPH 2021, I’d highly recommend giving the talk a watch (and then going to see all of the other cool Disney Animation talks this year)!
For anyone interested in the technique post-SIGGRAPH 2021, hopefully we’ll be able to get a version of the slides cleared for release by the studio at some point.
Wayne’s excellent implementations of the above techniques proved to be an enormous win for both rendering efficiency and artist workflows on Raya and the Last Dragon; I personally think we would have had enormous difficulties in hitting the lighting art direction on Raya and the Last Dragon if it weren’t for Wayne’s work.
I owe Wayne a huge debt of gratitude for letting me be a small part of this project; the discussions were very fun, seeing it all come together was very exciting, and helping put the techniques down on paper for the SIGGRAPH talk was an excellent exercise in figuring out how to communicate cutting edge research clearly.
A frame from Raya and the Last Dragon without our techniques (left), and with both our scattering and emission sampling applied (right). Both images are rendered using 32 spp per volume pass; surface passes are denoised and composited with non-denoised volume passes to isolate noise from volumes. A video version of this comparison is included in our talk's supplementary materials. For a larger still comparison, click here.
References
Marc Bryant, Ryan DeYoung, Wei-Feng Wayne Huang, Joe Longson, and Noel Villegas. 2021. The Atmosphere of Raya and the Last Dragon. In ACM SIGGRAPH 2021 Talks. Article 51.
Brent Burley, David Adler, Matt Jen-Yuan Chiang, Hank Driskill, Ralf Habel, Patrick Kelly, Peter Kutz, Yining Karl Li, and Daniel Teece. 2018. The Design and Evolution of Disney’s Hyperion Renderer. ACM Transactions on Graphics 37, 3 (Jul. 2018), Article 33.
Julian Fong, Magnus Wrenninge, Christopher Kulla, and Ralf Habel. 2017. Production Volume Rendering. In ACM SIGGRAPH 2017 Courses. Article 2.
This post is the second half of my two-part series about how I ported my hobby renderer (Takua Renderer) to 64-bit ARM and what I learned from the process.
In the first part, I wrote about my motivation for undertaking a port to arm64 in the first place and described the process I took to get Takua Renderer up and running on an arm64-based Raspberry Pi 4B.
I also did a deep dive into several topics that I ran into along the way, which included floating point reproducibility across different processor architectures, a comparison of arm64 and x86-64’s memory reordering models, and a comparison of how the same example atomic code compiles down to assembly in arm64 versus in x86-64.
In this second part, I’ll write about developments and lessons learned after I got my initial arm64 port working correctly on Linux.
We’ll start with how I got Takua Renderer up and running on arm64 macOS, and discuss various interesting aspects of arm64 macOS, such as Universal Binaries and Apple’s Rosetta 2 binary translation layer for running x86-64 binaries on arm64 macOS.
As noted in the first part of this series, my initial port of Takua Renderer to arm64 did not include Embree; after the initial port, I added Embree support using Syoyo Fujita’s embree-aarch64 project (which has since been superseded by official arm64 support in Embree v3.13.0).
In this post I’ll look into how Embree, a codebase containing tons of x86-64 assembly and SSE and AVX intrinsics, was ported to arm64.
I will also use this exploration of Embree as a lens through which to compare x86-64’s SSE vector extensions to arm64’s Neon vector extensions.
Finally, I’ll wrap up with some additional important details to keep in mind when writing portable code between x86-64 and arm64, and I’ll also provide some more performance comparisons featuring the Apple M1 processor.
Porting to arm64 macOS
At WWDC 2020 last year, Apple announced that Macs would be transitioning from using x86-64 processors to using custom Apple Silicon chips over a span of two years.
Apple Silicon chips package together CPU cores, GPU cores, and various other coprocessors and controllers onto a single die; the CPU cores implement arm64.
Actually, Apple Silicon implements a superset of arm64; there are some interesting extra special instructions that Apple has added to their arm64 implementation, which I’ll get to a bit later.
Similar to how Apple provided developers with preview hardware during the previous Mac transition from PowerPC to x86, Apple also announced that for this transition they would be providing Developer Transition Kits (DTKs) to developers in the form of special Mac Minis based on the iPad Pro’s A12Z chip.
I had been anticipating a Mac transition to arm64 for some time, so I ordered a Developer Transition Kit as soon as they were made available.
Since I had already gotten Takua Renderer up and running on arm64 on Linux, getting Takua Renderer up and running on the Apple Silicon DTK was very fast!
By far the most time consuming part of this process was just getting developer tooling set up and getting Takua’s dependencies built; once all of that was done, building and running Takua basically Just Worked™.
The only reason that getting developer tooling set up and getting dependencies built took a bit of work at the time was because this was just a week and a half after the entire Mac arm64 transition had even been announced.
Interestingly, the main stumbling block I ran into for most things on Apple Silicon macOS wasn’t the change to arm64 under the hood at all; the main stumbling block was… the macOS version number!
For the past 20 years, modern macOS (or Mac OS X as it was originally named) has used 10.x version numbers, but the first version of macOS to support arm64, macOS Big Sur, bumps the version number to 11.x.
This version number bump threw off a surprising number of libraries and packages!
Takua’s build system uses CMake and Ninja, and on macOS I get CMake and Ninja through MacPorts.
At the time, a lot of stuff in MacPorts wasn’t expecting an 11.x version number, so a bunch of stuff wouldn’t build, but fixing all of this just required manually patching build scripts and portfiles to expect an 11.x version number.
All of this pretty much got fixed within weeks of DTKs shipping out (and Apple actually contributed a huge number of patches themselves to various projects and stuff), but I didn’t want to wait at the time, so I just charged ahead.
Only three of Takua’s dependencies needed some minor patching to get working on arm64 macOS: TBB, OpenEXR, and Ptex.
TBB’s build script just had to be updated to detect arm64 as a valid architecture for macOS; I submitted a pull request for this fix to the TBB Github repo, but I guess Intel doesn’t really take pull requests for TBB.
It’s okay though; the fix has since shown up in newer releases of TBB.
OpenEXR ‘s build script had to be patched so that inlined AVX intrinsics wouldn’t be used when building for arm64 on macOS; I submitted a pull request for this fix to OpenEXR that got merged, although this fix was later rendered unnecessary by a fix in the final release of Xcode 12.
Finally, Ptex just needed an extra include to pick up the unlink() system call correctly from unistd.h on macOS 11.
This change in Ptex was needed going from macOS Catalina to macOS Big Sur, and it’s also merged into the mainline Ptex repository now.
Once I had all of the above out of the way, getting Takua Renderer itself building and running correctly on the Apple Silicon DTK took no time at all, thanks to my previous efforts to port Takua Renderer to arm64 on Linux.
At this point I just ran cmake and ninja and a minute later out popped a working build.
From the moment the DTK arrived on my doorstep, I only needed about five hours to get Takua Renderer’s arm64 version building and running on the DTK with all tests passing.
Considering that at that point, outside of Apple nobody had done any work to get anything ready yet, I was very pleasantly surprised that I had everything up and working in just five hours!
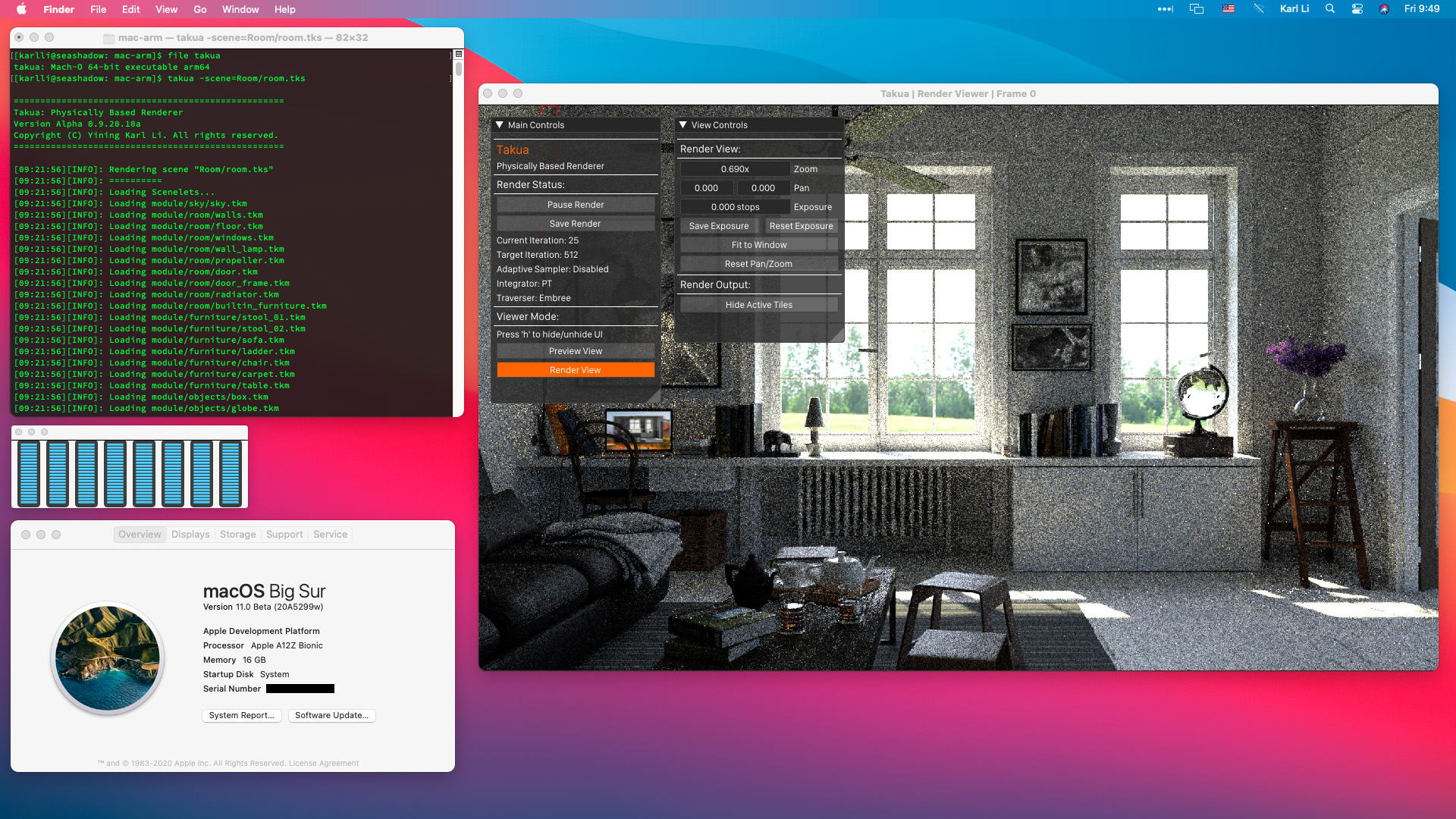
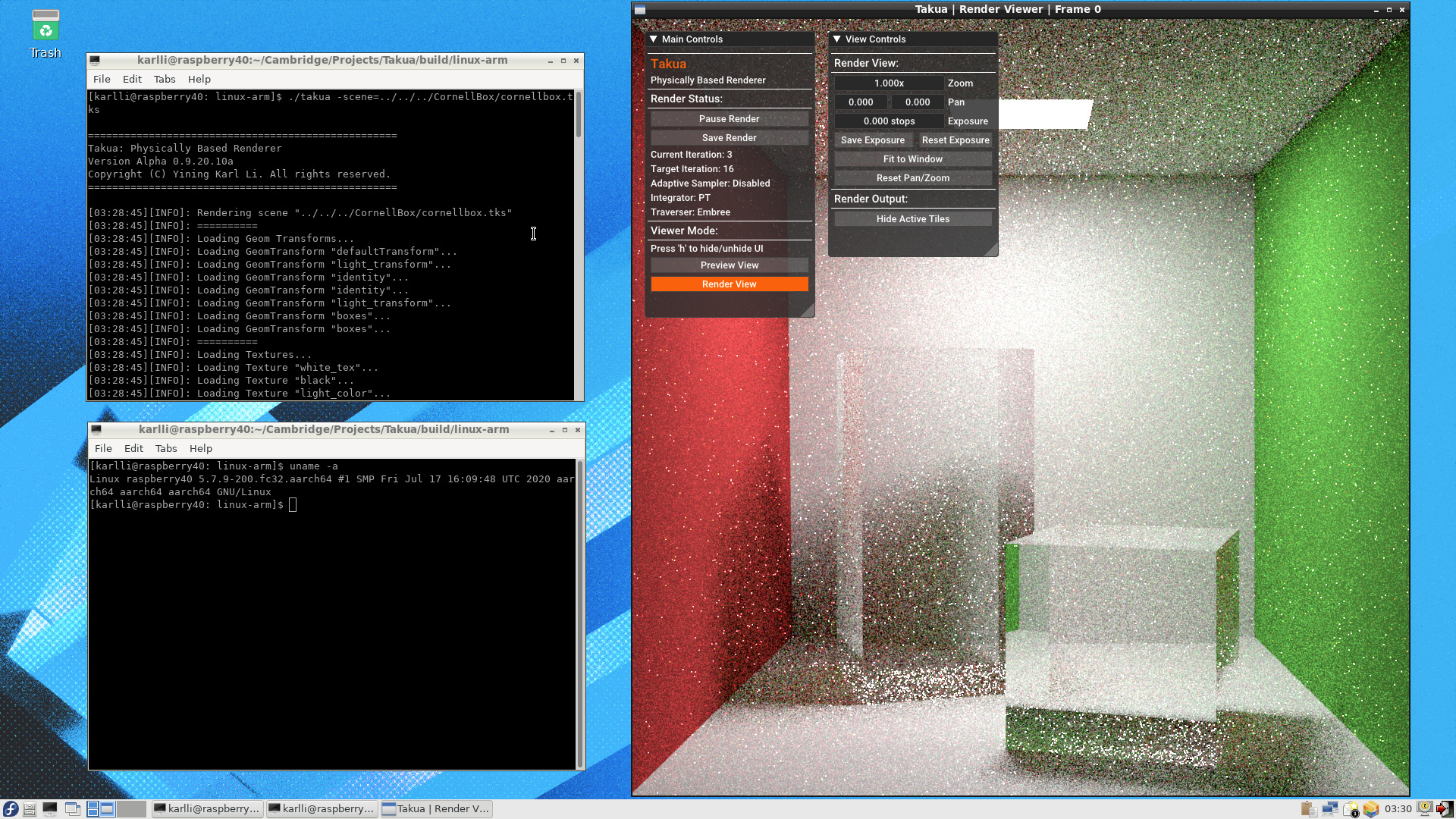
Figure 1 is a screenshot of Takua Renderer running on arm64 macOS Big Sur Beta 1 on the Apple Silicon DTK.
Universal Binaries
The Mac has now had three processor architecture migrations in its history; the Mac line began in 1984 based on Motorola 68000 series processors, transitioned from the 68000 series to PowerPC in 1994, transitioned again from PowerPC to x86 (and eventually x86-64) in 2006, and is now in the process of transitioning from x86-64 to arm64.
Apple has used a similar strategy in all three of these processor architecture migrations to smooth the process.
Apple’s general transition strategy consists of two major components: first, provide a “fat” binary format that packages code from both architectures into a single executable that can run on both architecture, and second, provide some way for binaries from the old architecture to run directly on the new architecture.
I’ll look into the second part of this strategy a bit later; in this section, we are interested in Apple’s fat binary format.
Apple calls their fat binary format Universal Binaries; specifically, Apple uses the name “Universal 2 “for the transition to arm64 since the original Universal Binary format was for the transition to x86.
Now that I had separate x86-64 and arm64 builds working and running on macOS, the next step was to modify Takua’s build system to automatically produce a single Universal 2 binary that could run on both Intel and Apple Silicon Macs.
Fortunately, creating Universal 2 binaries is very easy!
To understand why creating Universal 2 binaries can be so easy, we need to first understand at a high level how a Universal 2 binary works.
There actually isn’t much special about Universal 2 binaries per se, in the sense that multi-architecture support is actually an inherent feature of the Mach-O binary executable code file format that Apple’s operating systems all use.
A multi-architecture Mach-O binary begins with a header that declares the file as a multi-architecture file and declares how many architectures are present.
The header is immediately followed by a list of architecture “slices”; each slice is a struct describing some basic information, such as what processor architecture the slice is for, the offset in the file that instructions begin at for the slice, and so on [Oakley 2020].
After the list of architecture slices, the rest of the Mach-O file is pretty much like normal, except each architecture’s segments are concatenated after the previous architecture’s segments.
Also, Mach-O’s multi-architecture support allows for sharing non-executable resources between architectures.
So, because Universal 2 binaries are really just Mach-O multi-architecture binaries, and because Mach-O multi-architecture binaries don’t do any kind of crazy fancy interleaving and instead just concatenate each architecture after the previous one, all one needs to do to make a Universal 2 binary out of separate arm64 and x86-64 binaries is to concatenate the separate binaries into a single Mach-O file and set up the multi-architecture header and slices correctly.
Fortunately, a lot of tooling exists to do exactly the above!
The version of clang that Apple ships with Xcode natively supports building Universal Binaries by just passing in multiple -arch flags; one for each architecture.
The Xcode UI of course also supports building Universal 2 binaries by just adding x86-64 and arm64 to an Xcode project’s architectures list in the project’s settings.
For projects using CMake, CMake has a CMAKE_OSX_ARCHITECTURES flag; this flag defaults to whatever the native architecture of the current system is, but can be set to x86_64;arm64 to enable Universal Binary builds.
Finally, since the PowerPC to Intel transition, macOS has included a tool called lipo, which is used to query and create Universal Binaries; I’m fairly certain that the macOS lipo tool is based on the llvm-lipo tool that is part of the larger LLVM compiler project.
The lipo tool can combine any x86_64 Mach-O file with any arm64 Mach-O file to create a multi-architecture Universal Binary.
The lipo tool can also be used to “slim” a Universal Binary down into a single architecture by deleting architecture slices and segments from the Universal Binary.
Of course, when building a Universal Binary, any external libraries that have to be linked in also need to be Universal Binaries.
Takua has a relatively small number of direct dependencies, but unfortunately some of Takua’s dependencies pull in many more indirect (relative to Takua) dependencies; for example, Takua depends on OpenVDB, which in turn pulls in Blosc, zlib, Boost, and several other dependencies.
While some of these dependencies are built using CMake and are therefore very easy to build as Universal Binaries themselves, some other dependencies use older or bespoke build systems that can be difficult to retrofit multi-architecture builds into.
Fortunately, this problem is where the lipo tool comes in handy.
For dependencies that can’t be easily built as Universal Binaries, I just built arm64 and x86-64 versions separately and then combined the separate builds into a single Universal Binary using the lipo tool.
Once all of Takua’s dependencies were successfully built as Universal Binaries, all I had to do to get Takua itself to build as a Universal Binary was to add a check in my CMakeLists file to not use a couple of x86-64-specific compiler flags in the event of an arm64 target architecture.
Then I just set the CMAKE_OSX_ARCHITECTURES flag to x86_64;arm64, ran ninja, and out came a working Universal Binary!
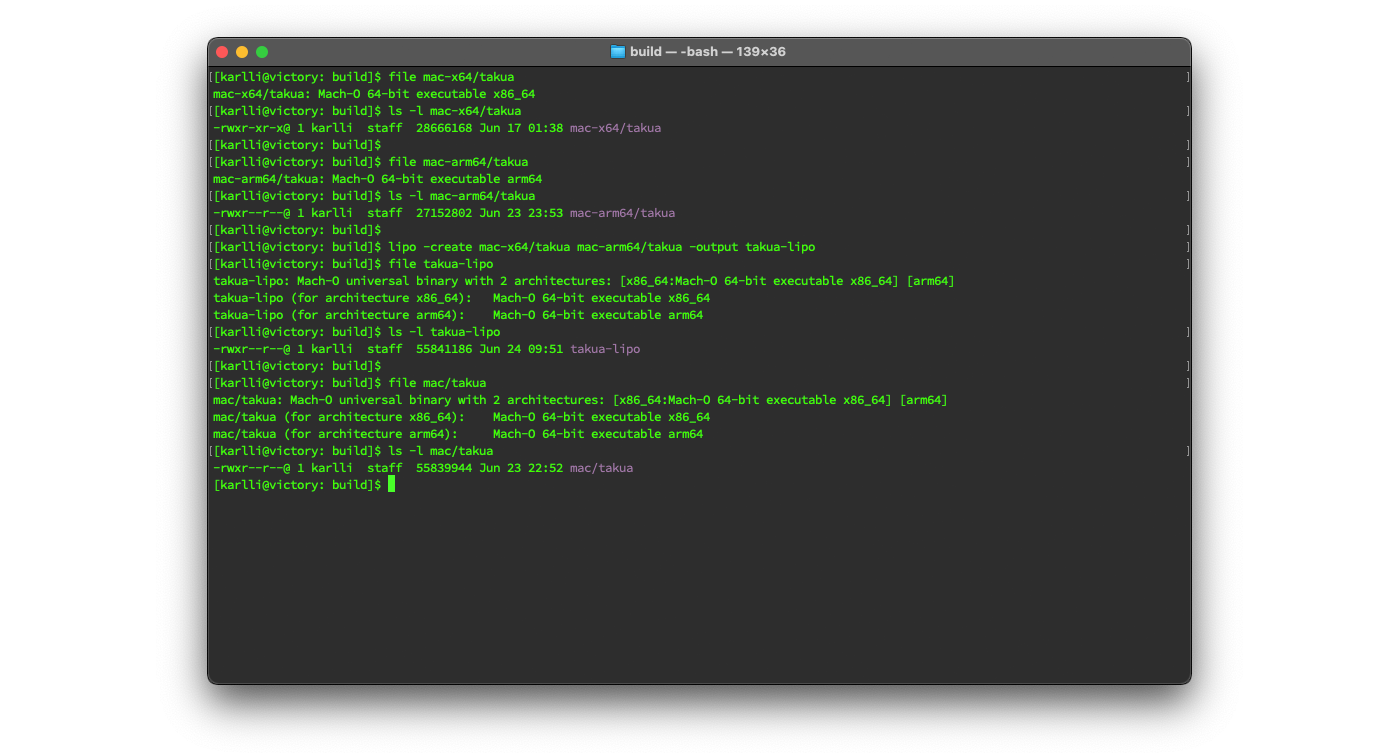
Figure 2 shows building Takua Renderer, checking that the current system architecture is an Apple Silicon Mac, using the lipo tool to see and confirm that the output Universal Binary contains both arm64 and x86-64 slices, and finally try running the Universal Binary Takua Renderer build:
Out of curiosity, I also tried creating separate x86-64-only and arm64-only builds of Takua and assembling them into a Universal Binary using the lipo tool and comparing the result with the build of Takua that was natively built as a Universal Binary.
In theory natively building as a Universal Binary should be able to produce a slightly more compact output binary compared with using the lipo tool, since a natively built Universal Binary should be able to share non-code resources between different architectures, whereas the lipo tool just blindly encapsulates two separate Mach-O files into a single multi-architecture Mach-O file.
In fact, you can actually use the lipo tool to combine completely different programs into a single Universal Binary; after all, lipo has absolutely no way of knowing whether or not the arm64 and x86-64 code you want to combine is actually even from the same source code or implements the same functionality.
Indeed, the native Universal Binary Takua is slightly smaller than the lipo-generated Universal Binary Takua.
The size difference is tiny (basically negligible) though, likely because Takua’s binary contains very few non-code resources.
Figure 3 shows creating a Universal Binary by combining separate x86-64 and arm64 builds of Takua together using the lipo tool versus a Universal Binary built natively as a Universal Binary; the lipo version is just a bit over a kilobyte larger than the native version, which is negligible relative to the overall size of the files.
Rosetta 2: Running x86-64 on Apple Silicon
While getting Takua Renderer building and running as a native arm64 binary on Apple Silicon only took me about five hours, actually running Takua for the first time in any form on Apple Silicon happened much faster!
Before I did anything to get Takua’s arm64 build up and running on my Apple Silicon DTK, the first thing I did was just copy over the x86-64 macOS build of Takua to see if it would run on Apple Silicon macOS through Apple’s dynamic binary translation layer, Rosetta 2.
I was very impressed to find that the x86-64 version of Takua just worked out-of-the-box through Rosetta 2, and even passed my entire test suite!
I have now had Takua’s native arm64 build up and running as part of a Universal 2 binary for around a year, but I recently circled back to examine how Takua’s x86-64 build works through Rosetta 2.
I wanted to get a rough idea of how Rosetta 2 works, and much like many of the detours that I took on the entire Takua arm64 journey, I stumbled into a good opportunity to compare x86-64 and arm64 and learn more about how the two are similar and how they differ.
For every processor architecture transition that the Mac had undertaken, Apple has provided some sort of mechanism to run binaries for the outgoing processor architecture on Macs based on the new architecture.
During the 68000 to PowerPC transition, Apple’s approach was to emulate an entire 68000 system at the lowest levels of the operating system on PowerPC; in fact, during this transition, PowerPC Macs even allowed 68000 and PowerPC code to call back and forth to each other and be interspersed within the same binary.
During the PowerPC to x86 transition, Apple introduced Rosetta, which worked by JIT-compiling blocks of PowerPC code into x86 on-the-fly at program runtime.
For the x86-64 to arm64 transition, Rosetta 2 follows in the same tradition as in the previous two architecture transitions.
Rosetta 2 has two modes: the first is an ahead-of-time recompiler that converts an entire x86-64 binary to arm64 upon first run of an x86-64 binary and caches the translated binary for later reuse.
The second mode Rosetta 2 has is a JIT translator, which is used for cases where the target program itself is also JIT-generating x86-64 code; obviously in these cases the target program’s JIT output cannot be recompiled to arm64 through an ahead-of-time process.
Apple does not publicly provide much information at all about how Rosetta 2 works under the hood.
Rosetta 2 is one of those pieces of Apple technology that basically “Just Works” well enough that the typical user never really has any need to know much about how it works internally, which is great for users but unfortunate for anyone that is more curious.
Fortunately though, Koh Nakagawa recently published a detailed analysis of Rosetta 2 produced through some careful reverse engineering work.
What I was interested in examining was how Rosetta 2’s output arm64 assembly looks compared with natively compiled arm64 assembly, so I’ll briefly summarize the relevant parts of how Rosetta 2 generates arm64 code.
There’s a lot more cool stuff about Rosetta 2, such as how the runtime and JIT mode works, that I won’t touch on here; if you’re interested, I’d highly recommend checking out Koh Nakagawa’s writeups.
When a user tries to run an x86-64 binary on an Apple Silicon Mac, Rosetta 2 first checks if this particular binary has already been translated by Rosetta 2 before; Rosetta 2 does this through a system daemon called oahd.
If Rosetta 2 has never encountered this particular binary before, oahd kicks off a new process called oahd-helper that carries out the ahead-of-time (AOT) binary translation process and caches the result in a folder located at /var/db/oah; cached AOT arm64 binaries are stored in subfolders named using a SHA-256 hash calculated from the contents and path of the original x86-64 binary.
If Rosetta 2 has encountered a binary before, as determined by finding an SHA-256 hash collision in /var/db/oah, then oahd just loads the cached AOT binary from before.
So what do these cached AOT binaries look like?
Unfortunately, /var/db/oah is by default not accessible to users at all, not even admin and root users.
Fortunately, like with all protected components of macOS, access can be granted by disabling System Integrity Protection (SIP).
I don’t recommend disabling SIP unless you have a very good reason to, since SIP is designed to protect core macOS files from getting damaged or modified, but for this exploration I temporarily disabled SIP just long enough to take a look in /var/db/oah.
Well, it turns out that the cached AOT binaries are just regular-ish arm64 Mach-O files named with an .aot extension; I say “regular-ish” because while the .aot files are completely normal Mach-O binaries, they cannot actually be executed on their own.
Attempting to directly run a .aot binary results in an immediate SIGKILL.
Instead, .aot binaries must be loaded by the Rosetta 2 runtime and require some special memory mapping to run correctly.
But that’s fine; I wasn’t interested in running the .aot file, I was interested in learning what it looks like inside, and since the .aot file is a Mach-O file, we can disassemble .aot files just like any other Mach-O file.
Let’s go through a simple example to compare how the same piece of C++ code compiles to arm64 natively, versus what Rosetta 2 generates from a x86-64 binary.
The simple example C++ code I’ll use here is the same basic atomic float addition implementation that I wrote about in my previous post; since that post already contains an exhaustive analysis of how this example compiles to both x86-64 and arm64 assembly, I figure that means I don’t need to go over all of that again and can instead dive straight into the Rosetta 2 comparison.
To make an actually executable binary though, I had to wrap the example addAtomicFloat() function in a simple main() function:
Modern versions of macOS’s Xcode Command Line Tools helpfully come with both otool and with LLVM’s version of objdump, both of which can be used to disassembly Mach-O binaries.
For this exploration, I used otool to disassemble arm64 binaries and objdump to disassembly x86-64 binaries.
I used different tools for disassembling x86-64 versus arm64 because of slightly different feature sets that I needed on each platform.
By default, Apple’s version of Clang uses newer ARMv8.1-A instructions like casal.
However, the version of objdump that Apple ships with the Xcode Command Line Tools only seems to support base ARMv8-a and doesn’t understand newer ARMv8.1-A instructions like casal, whereas otool does seem to know about ARMv8.1 instructions, hence using otool for arm64 binaries.
For x86-64 binaries, however, otool outputs x86-64 assembly using AT&T syntax, whereas I prefer reading x86-64 assembly in Intel syntax, which matches what Godbolt Compiler Explorer defaults to.
So, for x86-64 binaries, I used objdump, which can be set to output x86-64 assembly using Intel syntax with the -x86-asm-syntax=intel flag.
On both x86-64 and on arm64, I compiled the example in Listing 1 using the default Clang that comes with Xcode 12.5.1, which reports its version string as “Apple clang version 12.0.5 (clang-1205.0.22.11)”.
Note that Apple’s Clang version numbers have nothing to do with mainline upstream Clang version numbers; according to this table on Wikipedia, “Apple clang version 12.0.5” corresponds roughly with mainline LLVM/Clang 11.1.0.
Also, I compiled using the -O3 optimization flag.
Disassembling the x86-64 binary using objdump -disassemble -x86-asm-syntax=intel produces the following x86-64 assembly.
I’ve only included the assembly for the addAtomicFloat() function and not the assembly for the dummy main() function.
For readability, I have also replaced the offset for the jne instruction with a more readable label and added the label into the correct place in the assembly code:
<__Z14addAtomicFloatRNSt3__16atomicIfEEf>: # f0 is dword ptr [rdi], f1 is xmm0
push rbp # save address of previous stack frame
mov rbp, rsp # move to address of current stack frame
nop word ptr cs:[rax + rax] # multi-byte no-op, probably to align
# subsequent instructions better for
# instruction fetch performance
nop # no-op
.LBB0_1:
mov eax, dword ptr [rdi] # eax = *arg0 = f0.load()
movd xmm1, eax # xmm1 = eax = f0.load()
movdqa xmm2, xmm1 # xmm2 = xmm1 = eax = f0.load()
addss xmm2, xmm0 # xmm2 = (xmm2 + xmm0) = (f0 + f1)
movd ecx, xmm2 # ecx = xmm2 = (f0 + f1)
lock cmpxchg dword ptr [rdi], ecx # if eax == *arg0 { ZF = 1; *arg0 = arg1 }
# else { ZF = 0; eax = *arg0 };
# "lock" means all done exclusively
jne .LBB0_1 # if ZF == 0 goto .LBB0_1
movdqa xmm0, xmm1 # return f0 value from before cmpxchg
pop rbp # restore address of previous stack frame
ret # return control to previous stack frame address
nop
Listing 2: The addAtomicFloat() function from Listing 1 compiled to x86-64 using clang++ -O3 and disassembled using objdump -disassemble -x86-asm-syntax=intel, with some minor tweaks for formatting and readability. My annotations are also included as comments.
If we compare the above code with Listing 5 in my previous post, we can see that the above code matches what we got from Clang in Godbolt Compiler Explorer.
The only difference is the stack pointer pushing and popping code that happens in the beginning and end to make this function usable in a larger program; the core functionality in lines 8 through 18 of the above code matches the output from Clang in Godbolt Compiler Explorer exactly.
Next, here’s the assembly produced by disassembling the arm64 generated using Clang.
I disassembled the arm64 binary using otool -Vt; here’s the relevant addAtomicFloat() function with the same minor changes as in Listing 2 for more readable section labels:
__Z14addAtomicFloatRNSt3__16atomicIfEEf:
.LBB0_1:
ldar w8, [x0] // w8 = *arg0 = f0, non-atomically loaded
fmov s1, w8 // s1 = w8 = f0
fadd s2, s1, s0 // s2 = s1 + s0 = (f0 + f1)
fmov w9, s2 // w9 = s2 = (f0 + f1)
mov x10, x8 // x10 (same as w10) = x8 (same as w8)
casal w10, w9, [x0] // atomically read the contents of the address stored
// in x0 (*arg0 = f0) and compare with w10;
// if [x0] == w10:
// atomically set the contents of the
// [x0] to the value in w9
// else:
// w10 = value loaded from [x0]
cmp w10, w8 // compare w10 and w8 and store result in N
cset w8, eq // if previous instruction's compare was true,
// set w8 = 1
cmp w8, #0x1 // compare if w8 == 1 and store result in N
b.ne .LBB0_1 // if N==0 { goto .LBB0_1 }
mov.16b v0, v1 // return f0 value from ldar
ret
Listing 3: The addAtomicFloat() function from Listing 1 compiled to arm64 using clang++ -O3 and disassembled using otool -Vt, with some minor tweaks for formatting and readability. My annotations are also included as comments.
Note the use of the ARMv8.1-A casal instruction.
Apple’s version of Clang defaults to using ARMv8.1-A instructions when compiling for macOS because the M1 chip implements ARMv8.4-A, and since the M1 chip is the first arm64 processor that macOS supports, that means macOS can safely assume a more advanced minimum target instruction set.
Also, the arm64 assembly output in Listing 3 looks almost exactly identical structurally to the Godbolt Compiler Explorer Clang output in Listing 9 from my previous post.
The only differences are in small syntactical differences with how the mov instruction in line 20 specifies a 16 byte (128 bit) SIMD register, some different register choices, and a different ordering of fmov and mov instructions in lines 6 and 7.
Finally, let’s take a look at the arm64 assembly that Rosetta 2 generates through the AOT process described earlier.
Disassembling the Rosetta 2 AOT file using otool -Vt produces the following arm64 assembly; like before, I’m only including the relevant addAtomicFloat() function.
Since the code below switches between x and w registers a lot, remember that in arm64 assembly, x0-x30 and w0-w30 are really the same registers; x just means use the full 64-bit register, whereas w just means use the lower 32 bits of the x register with the same register number.
Also, the v registers are 128-bit vector registers that are separate from the x/y set of registers; s registers are the bottom 32 bits of v registers.
In my annotations, I’ll use x for both x and w registers, and I’ll use v for both v and s registers.
__Z14addAtomicFloatRNSt3__16atomicIfEEf:
str x5, [x4, #-0x8]! // store value at x5 to ((address in x4) - 8) and
// write calculated address back into x4
mov x5, x4 // x5 = address in x4
.LBB0_1
ldr w0, [x7] // x0 = *arg0 = f0, non-atomically loaded
fmov s1, w0 // v1 = x0 = f0
mov.16b v2, v1 // v2 = v1 = f0
fadd s2, s2, s0 // v2 = v2 + v0 = (f0 + f1)
mov.s w1, v2[0] // x1 = v2 = (f0 + f1)
mov w22, w0 // x22 = x0 = f0
casal w22, w1, [x7] // atomically read the contents of the address stored
// in x7 (*arg0 = f0) and compare with x22;
// if [x7] == x22:
// atomically set the contents of the
// [x7] to the value in x1
// else:
// x22 = value loaded from [x7]
cmp w22, w0 // compare x22 and x0 and store result in N
csel w0, w0, w22, eq // if N==1 { x0 = x0 } else { x0 = x22 }
b.ne .LBB0_1 // if N==0 { goto .LBB0_1 }
mov.16b v0, v1 // v0 = v1 = f0
ldur x5, [x4] // x5 = value at address in x4, using unscaled load
add x4, x4, #0x8 // add 8 to address stored in x4
ldr x22, [x4], #0x8 // x22 = value at ((address in x4) + 8)
ldp x23, x24, [x21], #0x10 // x23 = value at address in x21 and
// x24 = value at ((address in x21) + 8)
sub x25, x22, x23 // x25 = x22 - x23
cbnz x25, .LBB0_2 // if x22 != x23 { goto .LBB0_2 }
ret x24
.LBB0_2
bl 0x4310 // branch (with link) to address 0x4310
Listing 4: The x86-64 assembly from Listing 2 translated to arm64 by Rosetta 2's ahead-of-time translator. Disassembled using otool -Vt, with some minor tweaks for formatting and readability. My annotations are also included as comments.
In some ways, we can see similarities between the Rosetta 2 arm64 assembly in Listing 4 and the natively compiled arm64 assembly in Listing 3, but there are also a lot of things in the Rosetta 2 arm64 assembly that look very different from the natively compiled arm64 assembly.
The core functionality in lines 9 through 21 of Listing 4 bear a strong resemblance to the core functionality in lines 5 through 19 of of Listing 3; both versions use a fadd, followed by a casal instruction to implement the atomic comparison, then follow with a cmp to compare the expected and actual outcomes, and then have some logic about whether or not to jump back to the top of the loop.
However, if we look more closely at the core functionality in the Rosetta 2 version, we can see some oddities.
In preparing for the fadd instruction on line 9, the Rosetta 2 version does a fmov followed by a 16-bit mov into register v2, and then the fadd takes a value from v2, adds the value to what is in v0, and stores the result back into v2.
The 16-bit move is pointless!
Instead of two mov instructions and an fadd where the first source registers and destination registers are the same, a better version would be to omit the second mov instruction and instead just do fadd s2 s1 s0.
In fact, in Listing 3 we can see that the natively compiled version does in fact just use a single mov and do fadd s2 s1 s0.
So, what’s going on here?
Things begin to make more sense once we look at the x86-64 assembly that the Rosetta 2 version is translated from.
In Listing 2’s x86-64 version, the addss instruction only has two inputs because the first source register is always also the destination register.
So, the x86-64 version has no choice but to use a few extra mov instructions to make sure values that are needed later aren’t overwritten by the addss instruction; whatever value needs to be in xmm2 during the addss instruction must also be squirreled away in a second location if that value is still needed after addss is executed.
Since the Rosetta 2 arm64 assembly is a direct translation from the x86-64 assembly, the extra mov needed in the x86-64 version gets translated into the extraneous mov.16b in Listing 4, and the two-operand x86-64 addss gets translated into a strange looking fadd where the same register is duplicated for the first source and destination operands; this duplication is a direct one-to-one mapping to what addss does.
I think from the above we can see two very interesting things about Rosetta 2’s translation.
On one hand, the fact that the overall structure of the core functionality in the Rosetta 2 and natively compiled versions is so similar is very impressive, especially when considering that Rosetta 2 had absolutely no access to the original high-level C++ source code!
I guess my example function here is a very simple test case, but nonetheless I was impressed that Rosetta 2’s output overall isn’t too bad.
On the other hand though, the Rosetta 2 version does have small oddities and inefficiencies that arise from doing a direct mechanical translation from x86-64.
Since Rosetta 2 has no access to the original source code, no context for what the code does, and has no ability to build any kind of higher-level syntactic understanding, the best Rosetta 2 really can do is a direct mechanical translation with a relatively high level of conservatism with respect to preserving what the original x86-64 code is doing on an instruction-by-instruction basis.
I don’t think that this is actually a fault in Rosetta 2; I think it’s actually pretty much the only reasonable solution.
I don’t know how Rosetta 2’s translator is actually implemented internally, but my guess is that the translator is parsing the x86-64 machine code, generating some kind of IR, and then lowering that IR back to arm64 (who knows, maybe it’s even LLIR).
But, even if Rosetta 2 is generating some kind of IR, that IR at best can only correspond well to the IR that was generated by the last optimization pass in the original compilation to x86-64, and in any last optimization pass, a huge amount of higher level context is likely already lost from the original source program.
Short of doing heroic amounts of program analysis, there’s nothing Rosetta 2 can do about this lost higher level context, and even if implementing all of that program analysis was worthwhile (Which it almost certainly is not) there’s only so much that static analysis can do anyway.
I guess all of the above is a long way of saying: looking at the above example, I think Rosetta 2’s output is really impressive and surprisingly more optimal than I would have guessed before, but at the same time the inherent advantage that natively compiling to arm64 has is obvious.
However, all of the above is just looking at the core functionality of the original function.
If we look at the arm64 assembly surrounding this core functionality in Listing 4 though, we can see some truly strange stuff.
The Rosetta 2 version is doing a ton of pointer arithmetic and moving around addresses and stuff, and operands seem to be passed into the function using the wrong registers (x7 instead of x0).
What is this stuff all about?
The answer lies in how the Rosetta 2 runtime works, and in what makes a Rosetta 2 AOT Mach-O file different from a standard macOS Mach-O binary.
One key fundamental difference between Rosetta 2 AOT binaries and regular arm64 macOS binaries is that Rosetta 2 AOT binaries use a completely different ABI from standard arm64 macOS.
On Apple platforms, the ABI used for normal arm64 Mach-O binaries is largely based on the standard ARM-developed arm64 ABI [ARM Holdings 2015], with some small differences [Apple 2020] in function calling conventions and how some data types are implemented and aligned.
However, Rosetta 2 AOT binaries use an arm64-ized version of the System V AMD64 ABI, with a direct mapping between x86_64 and arm64 registers [Nakagawa 2021].
This different ABI means that intermixing native arm64 code and Rosetta 2 arm64 code is not possible (or at least not at all practical), and this difference is also the explanation for why the Rosetta 2 assembly uses unusual registers for passing parameters into the function.
In the standard arm64 ABI calling convention, registers x0 through x7 are used to pass function arguments 0 through 7, with the rest going on the stack.
In the System V AMD64 ABI calling convention, function arguments are passed using registers rdi, rsi, rdx, rcx, r8, and r9 for arguments 0 through 5 respectively, with everything else on the stack in reverse order.
In the arm64-ized version of the System V AMD64 ABI that Rosetta 2 AOT uses, the x86-64 rdi, rsi, rdx, rcx, r8, and r9 registers map to the arm64 x7, x6, x2, x1, x8, and x9, respectively [Nakagawa 2021].
So, that’s why in line 6 of Listing 4 we see a load from an address stored in x7 instead of x0, because x7 maps to x86-64’s rdi register, which is the first register used for passing arguments in the System V AMD64 ABI [OSDev 2018].
If we look at the corresponding instruction on line 9 of Listing 2, we can see that the x86-64 code does indeed use a mov instruction from the address stored in rdi to get the first function argument.
As for all of the pointer arithmetic and address trickery in lines 23 through 28 of Listing 4, I’m not 100% sure what it is for, but I have a guess.
Earlier I mentioned that .aot binaries cannot run like a normal binary and instead require some special memory mapping to work; I think all of this pointer arithmetic may have to do with that.
The way that the Rosetta 2 runtime interacts with the AOT arm64 code is that both the runtime and the AOT arm64 code are mapped into the same memory space at startup and the program counter is set to the entry point of the Rosetta 2 runtime; while running, the AOT arm64 code frequently can jump back into the Rosetta 2 runtime because the Rosetta 2 runtime is what handles things like translating x86_64 addresses into addresses in the AOT arm64 code [Nakagawa 2021].
The Rosetta 2 runtime also directs system calls to native frameworks, which helps improve performance; this property of the Rosetta 2 runtime means that if an x86-64 binary does most of its work by calling macOS frameworks, the translated Rosetta 2 AOT binary can still run very close to native speed (as an interesting aside: Microsoft is adding a much more generalized version of this concept to Windows 11’s counterpart to Rosetta 2: Windows 11 on Arm will allow arbitrary mixing of native arm64 code and translated x86-64 code [Sweetgall 2021].
Finally, when a Rosetta 2 AOT binary is run, not only the arm64 and Rosetta 2 runtime are mapped into the running program memory; the original x86-64 binary is mapped in as well.
The AOT binary that Rosetta 2 generates does not actually contain any constant data from the original x86-64 binary; instead, the AOT file references the constant data from the x86-64 binary, which is why the x86-64 binary also needs to be loaded in.
My guess is that the pointer arithmetic stuff happening in the end of Listing 4 is possibly either to calculate offsets to stuff in the x86-64 binary, or to calculate offsets into the Rosetta 2 runtime itself.
Now that we have a better understanding of what Rosetta 2 is actually doing under the hood and how good the translated arm64 code is compared with natively compiled arm64 code, how does Rosetta 2 actually perform in the real world?
I compared Takua Renderer running as native arm64 code versus as x86-64 code running through Rosetta 2 on four different scenes, and generally running through Rosetta 2 yielded about 65% to 70% of the performance of running as native arm64 code.
The results section at the end of this post contains the detailed numbers and data.
Generally, I’m very impressed with this amount of performance for emulating x86-64 code on an arm64 processor, especially when considering that with high-performance code like Takua Renderer, Rosetta 2 has close to zero opportunities to provide additional performance by calling into native system frameworks.
As can be seen in the data in the results section, even more impressive is the fact that even running at 70% of native speed, x86-64 Takua Renderer running on the M1 chip through Rosetta 2 is often on-par with or even faster than x86-64 Takua Renderer running natively on a contemporaneous current-generation 2019 16-inch MacBook Pro with a 6-core Intel Core i7-9750H processor!
TSO Memory Ordering on the M1 Processor
As I covered extensively in my previous post, one major crucial architectural difference between arm64 and x86-64 is in memory ordering: arm64 is a weakly ordered architecture, whereas x86-64 is a strongly ordered architecture [Preshing 2012].
Any system emulating x86-64 binaries on an arm64 processor needs to overcome this memory ordering difference, which means emulating strong memory ordering on a weak memory architecture.
Unfortunately, doing this memory ordering emulation in software is extremely difficult and extremely inefficient. since emulating strong memory ordering on a weak memory architecture means providing stronger memory ordering guarantees than the hardware actually provides.
This memory ordering emulation is widely understood to be one of the main reasons why Microsoft’s x86 emulation mode for Windows on Arm incurs a much higher performance penalty compared with Rosetta 2, even though the two systems have broadly similar architectures [Hickey et al. 2021] at a high level.
Apple’s solution to the difficult problem of emulating strong memory ordering in software was to… just completely bypass the problem altogether.
Rosetta 2 does nothing whatsoever to emulate strong memory ordering in software; instead, Rosetta 2 provides strong memory ordering through hardware.
Apple’s M1 processor has an unusual feature for an ARM processor: the M1 processor has optional total store memory ordering (TSO) support!
By default, the M1 processor only provides the weak memory ordering guarantees that the arm64 architecture specifies, but for x86-64 binaries running under Rosetta 2, the M1 processor is capable of switching to strong memory ordering in hardware on a core-by-core basis.
This capability is a great example of the type of hardware-software integration that Apple is able to accomplish by owning and building the entire tech stack from the software all the way down to the silicon.
Actually, the M1 is not the first Apple Silicon chip to have TSO support.
The A12Z chip that was in the Apple Silicon DTK also has TSO support, and the A12Z is known to be a re-binned but otherwise identical variant of the A12X chip from 2018, so we can likely safely assume that the TSO hardware support has been present (albeit unused) as far back as the 2018 iPad Pro!
However, the M1 processor’s TSO implementation does have a significant leg up on the implementation in the A12Z.
Both the M1 and the A12Z implement a version of ARM’s big.LITTLE technology, where the processor contains two different types of CPU cores: lower-power energy-efficient cores, and high-power performance cores.
On the A12Z, hardware TSO support is only implemented in the high-power performance cores, whereas in the M1, hardware TSO support is implement on both the efficiency and performance cores.
As a result, on the A12Z-based Apple Silicon DTK, Rosetta 2 can only use four out of eight total CPU cores on the chip, whereas on M1-based Macs, Rosetta 2 can use all eight CPU cores.
I should mentioned here that, interestingly, the A12Z and M1 are actually not the first ARM CPUs to implement TSO as the memory model [Threedots 2021].
Remember, when ARM specifies weak ordering in the architecture, what this actually means is that any arm64 implementation can actually choose to have any kind of stronger memory model since code written for a weaker memory model should also work correctly on a stronger memory model; only going the other way doesn’t work.
NVIDIA’s Denver and Carmel CPU microarchitectures (found in various NVIDIA Tegra and Xaviar system-on-a-chips) are also arm64 designs that implement a sequentially consistency memory model.
If I had to guess, I would guess that Denver and Carmel’s sequential consistency memory model is a legacy of the Denver Projects’s origins as a project to build an x86-64 CPU; the project was shifted to arm64 before release.
Fujitsu’s A64FX processor is another arm64 design that implements TSO as its memory model, which makes sense since the A64FX processor is meant for use in supercomputers as a successor to Fujitsu’s previous SPARC-based supercomputer processors, which also implemented TSO.
However, to the best of my knowledge, Apple’s A12Z and M1 are unique in their ability to execute in both the usual weak ordering mode and TSO mode.
To me, probably the most interesting thing about hardware TSO support in Apple Silicon is that switching ability.
Even more interesting is that the switching ability doesn’t require a reboot or anything like that- each core can be independently switched between strong and weak memory ordering on-the-fly at runtime through software.
On Apple Silicon processors, hardware TSO support is enabled by modifying a special register named actlr_el1; this register is actually defined by the arm64 specification as an implementation-defined auxiliary control register.
Since actlr_el1 is implementation-defined, Apple has chosen to use it for toggling TSO and possibly for toggling other, so far publicly unknown special capabilities.
However, the actlr_el1 register, being a special register, cannot be modified by normal code; modifications to actlr_el1 can only be done by the kernel, and the only thing in macOS that the kernel enables TSO for is Rosetta 2…
…at least by default!
Shortly after Apple started shipping out Apple Silicon DTKs last year, Saagar Jha figured out how to allow any program to toggle TSO mode through a custom kernel extension.
The way the TSOEnabler kext works is extremely clever; the kext searches through the kernel to find where the kernel is modifying actlr_el1 and then traces backwards to figure out what pointer the kernel is reading a flag from for whether or not to enable TSO mode.
Instead of setting TSO mode itself, the kext then intercepts the pointer to the flag and writes to it, allowing the kernel to handle all of the TSO mode setup work since there’s some other stuff that needs to happen in addition to modifying actlr_el1.
Out of sheer curiosity, I compiled the TSOEnabler kext and installed it on my M1 Mac Mini to give it a try!
I don’t suggest installing and using TSOEnabler casually, and definitely not for normal everyday use; installing a custom self-compiled, unsigned kext on modern macOS requires disabling SIP.
However, I already had SIP disabled due to my earlier Rosetta 2 AOT exploration, and so I figured why not give this a shot before I reset everything and reenable SIP.
The first thing I wanted to try was a simple test to confirm that the TSOEnabler kext was working correctly.
In my last post, I wrote about a case where weak memory ordering was exposing a bug in some code written around incrementing an atomic integer; the “canonical” example of this specific type of situation is Jeff Preshing’s multithreaded atomic integer incrementer example using std::memory_order_relaxed.
I adapted Jeff Preshing’s example for my test; in this test, two threads both increment a shared integer counter 1000000 times, with exclusive access to the integer guarded using an atomic integer flag.
Operations on the atomic integer flag use std::memory_order_relaxed.
On strongly-ordered CPUs, using std::memory_order_relaxed works fine and at the end of the program, the value of the shared integer counter is always 2000000 as expected.
However, on weakly-ordered CPUs, weak memory ordering means that two threads can end up in a race condition to increment the shared integer counter; as a result, on weakly-ordered CPUs, at the end of the program the value of the shared integer counter is very often something slightly less than 2000000.
The key modification I made to this test program was to enable the M1 processor’s hardware TSO mode for each thread; if hardware TSO mode is correctly enabled, then the value of the shared integer counter should always end up being 2000000.
If you want to try for yourself, Listing 5 below includes the test program in its entirety; compile using c++ tsotest.cpp -std=c++11 -o tsotest.
The test program takes a single input parameter: 1 to enable hardware TSO mode, and anything else to leave TSO mode disabled.
Remember, to use this program, you must have compiled and installed the TSOEnabled kernel extension mentioned above.
Listing 5: Jeff Preshing's weakly ordered atomic integer test program, modified to support using the M1 processor's hardware TSO mode.
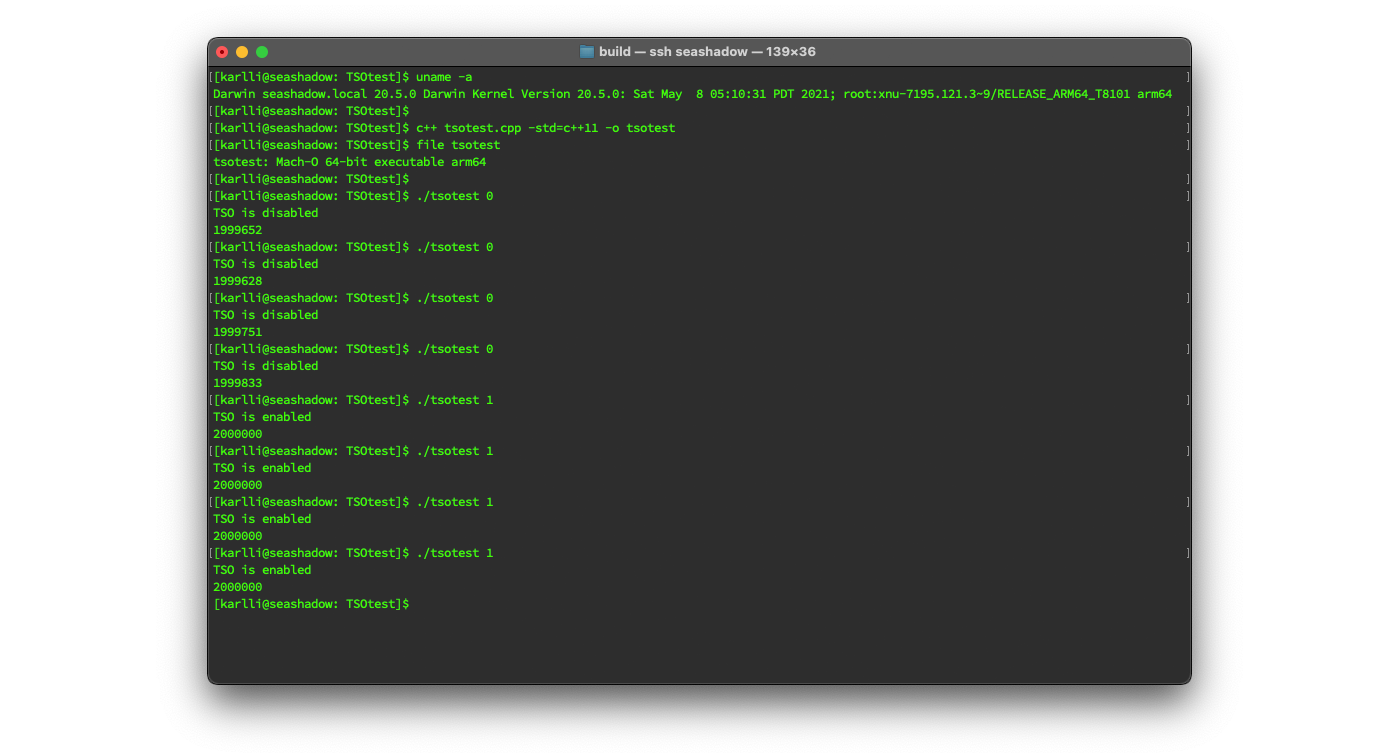
Running my test program indicated that the kernel extension was working properly!
In the screenshot below, I check that the Mac I’m running on has an arm64 processor, then I compile the test program and check that the output is a native arm64 binary, and then I run the test program four times each with and without hardware TSO mode enabled.
As expected, with hardware TSO mode disabled, the program counts slightly less than 2000000 increments on the shared atomic counter, whereas with hardware TSO mode enabled, the program counts exactly 2000000 increments every time:
Being able to enable hardware TSO mode in a native arm64 binary outside of Rosetta 2 actually does have some practical uses.
After I confirmed that the kernel extension was working correctly, I temporarily hacked hardware TSO mode into Takua Renderer’s native arm64 version, which allowed me to further verify that everything was working correctly with all of the various weakly ordered atomic fixes that I described in my previous post.
As mentioned in my previous post, comparing renders across different processor architectures is difficult for a variety of reasons, and previously comparing Takua Renderer running on a weakly ordered CPU versus on a strongly ordered CPU required comparing renders made on arm64 versus renders made on x86-64.
Using the M1’s hardware TSO mode though, I was able to compare renders made on exactly the same processor, which confirmed that everything works correctly!
After doing this test, I then removed the hardware TSO mode from Takua Renderer’s native arm64 version.
One silly idea I tried was to disable hardware TSO mode from inside of Rosetta 2, just to see what would happen.
Rosetta 2 does not support running x86-64 kernel extensions on arm64; all macOS kernel extensions must be native to the architecture they are running on.
However, as mentioned earlier, the Rosetta 2 runtime bridges system framework calls from inside of x86-64 binaries to their native arm64 counterparts, and this includes sysctl calls!
So we can actually call sysctlbyname("kern.tso_enable") from inside of an x86-64 binary running through Rosetta 2, and Rosetta 2 will pass the call along correctly to the native TSOEnabler kernel extension, which will then properly set hardware TSO mode.
For a simple test, I added a bit of code to test if a binary is running under Rosetta 2 or not and compiled the test program from Listing 5 for x86-64.
For the sake of completeness, here is how to check if a process is running under Rosetta 2; this code sample was provided by Apple in a WWDC 2020 talk about Apple Silicon:
// Use "sysctl.proc_translated" to check if running in Rosetta
// Returns 1 if running in Rosetta
int processIsTranslated() {
int ret = 0;
size_t size = sizeof(ret);
// Call the sysctl and if successful return the result
if (sysctlbyname("sysctl.proc_translated", &ret, &size, NULL, 0) != -1)
return ret;
// If "sysctl.proc_translated" is not present then must be native
if (errno == ENOENT)
return 0;
return -1;
}
Listing 6: Example code from Apple on how to check if the current process is running through Rosetta 2.
In Figure 5, I build the test program from Listing 5 as an x86-64 binary, with the Rosetta 2 detection function from Listing 6 added in.
I then check that the system architecture is arm64 and that the compiled program is x86-64, and run the test program with TSO disabled from inside of Rosetta 2.
The program reports that it is running through Rosetta 2 and reports that TSO is disabled, and then proceeds to report slightly less than 2000000 increments to the shared atomic counter:
Of course, being able to disable hardware TSO mode from inside of Rosetta 2 is only a curiosity; I can’t really think of any practical reason why anyone would ever want to do this.
I guess one possible answer is to try to claw back some performance whilst running through Rosetta 2, since the hardware TSO mode does have a tangible performance impact, but this answer isn’t actually valid, since there is no guarantee that x86-64 binaries running through Rosetta 2 will work correctly with hardware TSO mode enabled.
The simple example here only works precisely because it is extremely simple; I also tried hacking disabling hardware TSO mode into the x86-64 version of Takua Renderer and running that through Rosetta 2.
The result was that this hacked version of Takua Renderer would run for only a fraction of a second before running into a hard crash from somewhere inside of TBB.
More complex x86-64 programs with hardware TSO mode not working correctly or even crashing shouldn’t be surprising, since the x86-64 code itself can have assumptions about strong memory ordering baked into whatever optimizations the code was compiled with.
As mentioned earlier, running a program written and compiled with weak memory ordering assumptions on a stronger memory model should work correctly, but running a program written and compiled with strong memory ordering assumptions on a weaker memory model can cause problems.
Speaking of the performance of hardware TSO mode, the last thing I tried was measuring the performance impact of enabling hardware TSO mode.
I hacked enabling hardware TSO mode into the native arm64 version of Takua Renderer, with the idea being that by comparing the Rosetta 2, custom TSO-enabled native arm64, and default TSO-disabled native arm64 versions of Takua Renderer, I could get a better sense of exactly how much performance cost there is to running the M1 with TSO enabled, and how much of the performance cost of Rosetta 2 comes from less efficient translated arm64 code versus from TSO-enabled mode.
The results section at the end of this post contains the exact numbers and data for the four scenes that I tested; the general trend I found was that native arm64 code with hardware TSO enabled ran about 10% to 15% slower than native arm64 code with hardware TSO disabled.
When comparing with Rosetta 2’s overall performance, I think we can reasonably estimate that on the M1 chip, hardware TSO is responsible for somewhere between a third to a half of the performance discrepancy between Rosetta 2 and native weakly ordered arm64 code.
Apple Silicon’s hardware TSO mode is a fascinating example of Apple extending the base arm64 architecture and instruction set to accelerate application-specific needs.
Hardware TSO mode to support and accelerate Rosetta 2 is just the start; Apple Silicon is well known to already contain some other interesting custom extensions as well.
For example, Apple Silicon contains an entire new, so far undocumented arm64 ISA extension centered around doing fast matrix operations for Apple’s “Accelerate” framework, which supports various deep learning and image procesing applications [Johnson 2020].
This extension, called AMX (for Apple Matrix coprocessor), is separate but likely related to the “Neural Engine” hardware [Engheim 2021] that ships on the M1 chip alongside the M1’s arm64 processor and custom Apple-designed GPU.
Recent open-source code releases from Apple also hint at future Apple Silicon chips having dedicated built-in hardware for doing branch predicion around Objective C’s objc_msgSend, which would considerably accelerate message passing in Cocoa apps.
Embree on arm64 using sse2neon
As mentioned earlier, porting Takua and Takua’s dependencies was relatively easy and straightforward and in large part worked basically out-of-the-box, because Takua and most of Takua’s dependencies are written in vanilla C++.
Gotchas like memory-ordering correctness in atomic and multithreaded code aside, porting vanilla C++ code between x86-64 and arm64 largely just involves recompiling, and popular modern compilers such as Clang, GCC, and MSVC all have mature, robust arm64 backends today.
However, for code written using inline assembly or architecture-specific vector SIMD intrinsics, recompilation is not enough to get things working on a different processor architecture.
A huge proportion of the raw compute power in modern processors is actually located in vector SIMD instruction set extensions, such as the various SSE and AVX extensions found in modern x86-64 processors and the NEON and upcoming SVE extensions found in arm64.
For workloads that can benefit from vectorization, using SIMD extensions means up to a 4x speed boost over scalar code when using SSE or NEON, and potentially even more using AVX or SVE.
One way to utilize SIMD extensions is just to write scalar C++ code like normal and let the compiler auto-vectorize the code at compile-time.
However, relying on auto-vectorization to leverage SIMD extensions in practice can be surprisingly tricky.
In order for compilers to be able to efficiently auto-vectorize code that was written to be scalar, compilers need to be able to deduce and infer an enormous amount of context and knowledge about what the code being compiled actually does, and doing this kind of work is extremely difficult and extremely prone to defeat by edge cases, complex scenarios, or even just straight up implementation bugs.
The end result is that getting scalar C++ code to go through auto-vectorization well in practice ends up requiring a lot of deep knowledge about how the compiler’s auto-vectorization implementation actually works under the hood, and small innocuous changes can often suddenly lead to the compiler falling back to generating completely scalar assembly.
Without a robust performance test suite, these fallbacks can happen unbeknownst to the programmer; I like the term that my friend Josh Filstrup uses for these scenarios: “real rugpull moments”.
Most high-performance applications that require good vectorization usually rely on at least one of several other options: write code directly in assembly utilizing SIMD instructions, write code using SIMD intrinsics, or write code for use with ISPC: the Intel SPMD Program Compiler.
Writing SIMD code directly in assembly is more or less just like writing regular assembly, just with different instructions and wider registers; SSE uses XMM registers and many SSE instructions end in either SS or PS, AVX uses ZMM registers, and NEON uses D and Q registers.
Since writing directly in assembly is often not desirable for a variety of readability and ease-of-use reasons, writing vector code directly in assembly is not nearly as common as writing vector code in normal C or C++ using vector intrinsics.
Vector intrinsics are functions that look like regular functions from the outside, but within the compiler have a direct one-to-one or near one-to-one mapping to specific assembly instructions.
For SSE and AVX, vector intrinsics are typically found in headers named using the pattern *mmintrin.h, where * is a letter of the alphabet corresponding to a specific subset or version of either SSE of AVX (for example, x for SSE, e for SSE2, n for SSE4.2, i for AVX, etc.).
For NEON, vector intrinsics are typically found in arm_neon.h.
Vector intrinsics are commonly found in many high-performance codebases, but another powerful and increasingly popular way to vectorize code is by using ISPC.
ISPC compiles a special variant of the C programming language using a SPMD, or single-program-multiple-data, programming model compiled to run on SIMD execution units; the idea is that an ISPC program describes what a single lane in a vector unit does, and ISPC itself takes care of making that program run across all of the lanes of the vector unit [Pharr and Mark 2012].
While this may sound superficially like a form of auto-vectorization, there’s a crucial difference that makes ISPC far more reliable in outputting good vectorized assembly: ISPC bakes a vectorization-friendly programming model directly into the language itself, whereas normal C++ has no such affordances that C++ compilers can rely on.
This SPMD model is broadly very similar to how writing a GPU kernel works, although there are some key differences between SPMD as a programming model and the SIMT model that GPU run on (namely, a SPMD program can be at a different point on each lane, whereas a SIMT program keeps the progress across all lanes in lockstep).
A big advantage of using ISPC over vector intrinsics or vector assembly is that ISPC code is basically just normal C code; in fact, ISPC programs can often compile as normal scalar C code with little to no modification.
Since the actual transformation to vector assembly is up to the compiler, writing code for ISPC is far more processor architecture independent than vector intrinsics are; ISPC today includes backends to generate SSE, AVX, and NEON binaries.
Matt Pharr has a great blog post series that goes into much more detail about the history and motivations behind ISPC and the benefits of using ISPC.
In general, graphics workloads tend to fit the bill well for vectorization, and as a result, graphics libraries often make extensive use of SIMD instructions (actually, a surprisingly large number of problem types can be vectorized, including even JSON parsing).
Since SIMD intrinsics are architecture-specific, I didn’t fully expect all of Takua’s dependencies to compile right out of the box on arm64; I expected that a lot of them would contain chunks of code written using x86-64 SSE and/or AVX intrinsics!
However, almost all of Takua’s dependencies compiled without a problem either because they provided arm64 NEON or scalar C++ fallback codepaths for every SSE/AVX codepath, or because they rely on auto-vectorization by the compiler instead of using intrinsics directly.
OpenEXR is an example of the former, while OpenVDB and OpenSubdiv are examples of the latter.
Embree was the notable exception: Embree is heavily vectorized using code implemented directly using SSE and/or AVX intrinsics with no alternative scalar C++ or arm64 NEON fallback, and Embree also provides an ISPC interfaces.
Starting with Embree v3.13.0, Embree now provides an arm64 NEON codepath as well, but at the time I first ported Takua to arm64, Embree didn’t come with anything other than SSE and AVX implementations.
Fortunately, Embree is actually written in such a way that porting Embree to different processor architectures with different vector intrinsics is, at least in theory, relatively straightforward.
The Embree codebase internally is written as several different “layers”, where the bottommost layer is located in embree/common/simd/ in the Embree source tree.
As one might be able to guess from the name, this bottommost layer is where all of the core SIMD functionality in Embree is implemented; this part of the codebase implements SIMD wrappers for things like 4/8/16 wide floats, SIMD math operations, and so on.
The rest of the Embree codebase doesn’t really contain many direct vector intrinsics at all; the parts of Embree that actually implement BVH construction and traversal and ray intersection all call into this base SIMD library.
As suggested by Ingo Wald in a 2018 blog post, porting Embree to use something other than SSE/AVX mostly requires just reimplementing this base SIMD wrapper layer, and the rest of the Embree should more or less “just work”.
In his blog post, Ingo mentioned experimenting with replacing all of Embree’s base SIMD layer with scalar implementations of all of the vectorized code.
Back in early 2020, as part of my effort to get Takua up and running on arm64 Linux, I actually tried doing a scalar rewrite of the base SIMD layer of Embree as well as a first attempt at porting to arm64.
Overall the process to rewrite to scalar was actually very straightforward; most things were basically just replacing a function that did something with float4 inputs using SSE instructions with a simple loop that iterates over the four floats in a float4.
I did find that in addition to rewriting all of the SIMD wrapper functions to replace SSE intrinsics with scalar implementations, I also had to replace some straight-up inlined x86-64 assembly with equivalent compiler intrinsics; basically all of this code lives in common/sys/intrinsics.h.
None of the inlined assembly replacement was very complicated either though, most of it was things like replacing an inlined assembly call to x86-64’s bsf bit-scan-forward instruction with a call to the more portable __builtin_ctz() integer trailing zero counter builin compiler function.
Embree’s build system also required modifications; since I was just doing this as an initial test, I just did a terribly hack-job on the CMake scripts and, with some troubleshooting, got things building and running on arm64 Linux.
Unfortunately, the performance of my quick-and-rough scalar Embree port was… very disappointing.
I had hoped that the compiler would be able to do a decent job of autovectorizing the scalar reimplementations of all of the SIMD code, but overall my scalar Embree port on x86-64 was basically between three to four times slower than standard SSE Embree, which indicated that the compiler basically hadn’t effectively autovectorized anything at all.
This level of performance regression basically meant that my scalar Embree port wasn’t actually significantly faster than Takua’s own internal scalar BVH implementation; the disappointing performance combined with how hacky and rough my scalar Embree port was led me to abandon using Embree on arm64 Linux for the time being.
A short while later in the spring of 2020 though, I remembered that Syoyo Fujita had already succesfully ported Embree to arm64 with vectorization support!
Actually, Syoyo had started his Embree-aarch64 fork three years earlier in 2017 and had kept the project up-to-date with each new upstream official Embree release; I had just forgotten about the project until it popped up in my Twitter feed one day.
The approach that Syoyo took to getting vectorization working in the Embree-aarch64 fork was by using the sse2neon project, which implements SSE intrinsics on arm64 using NEON instructions and serves as a drop-in replacement for the various x86-64 *mmintrin.h headers.
Using sse2neon is actually the same strategy that had previously been used by Martin Chang in 2017 to port Embree 2.x to work on arm64; Martin’s earlier effort provided the proof-of-concept that paved the way for Syoyo to fork Embree 3.x into Embree-aarch64.
Building the Embree-aarch64 fork on arm64 worked out-of-the-box, and on my Raspberry Pi 4, using Embree-aarch64 with Takua’s Embree backend produced a performance increase over Takua’s internal BVH implementation that was in the general range of what I expected.
Taking a look at the process that was taken to get Embree-aarch64 to a production-ready state with results that matched x86-64 Embree exactly provides a lot of interesting insights into how NEON works versus how SSE works.
In my previous post I wrote about how getting identical floating point behavior between different processor architectures can be challenging for a variety of reasons; getting floating point behavior to match between NEON and SSE is even harder!
Various NEON instructions such as rcp and rsqt have different levels of accuracy from their corresponding SSE counterparts, which required the Embree-aarch64 project to implement more accurate versions of some SSE intrinsics than what sse2neon provided at the time; a lot of these improvements were later contributed back to sse2neon.
I originally was planning to include a deep dive into comparing SSE, NEON, ISPC, sse2neon, and SSE instructions running on Rosetta 2 as part of this post, but the writeup for that comparison has now gotten so large that it’s going to have to be its own post as a later follow-up to this post; stay tuned!
As a bit of an aside: the history of the sse2neon project is a great example of a community forming to build an open-source project around a new need.
The sse2neon project was originally started by John W. Ratcliff at NVIDIA along with a few other NVIDIA folks and implemented only a small subset of SSE that was just enough for their own needs.
However, after posting the project to Github with the MIT license, a community gradually formed around sse2neon and fleshed it out into a full project with full coverage of MMX and all versions of SSE from SSE1 all the way through SSE4.2.
Over the years sse2neon has seen contributions and improvements from NVIDIA, Amazon, Google, the Embree-aarch64 project, the Blender project, and recently Apple as part of Apple’s larger slew of contributions to various projects to improve arm64 support for Apple Silicon.
Starting with Embree v3.13.0, released in May 2021, the official main Embree project now has also gained full support for arm64 NEON; I have since switched Takua Renderer’s arm64 builds from using the Embree-aarch64 fork to using the new official arm64 support in Embree v3.13.0.
The approach the official Embree project takes is directly based off of the work that Syoyo Fujita and others did in the Embree-aarch64 fork; sse2neon is used to emulate SSE, and the same math precision improvements that were made in Embree-aarch64 were also adopted upstream by the official Embree project.
Much like Embree-aarch64, the arm64 NEON backend for Embree v3.13.0 does not include ISPC support, even though ISPC has an arm64 NEON backend as well; maybe this will come in the future.
Brecht Van Lommel from the Blender project seems to have done most of the work to upstream Embree-aarch64’s changes, with additional work and additional optimizations from Sven Woop on the Intel Embree team.
Interestingly and excitingly, Apple also recently submitted a patch to the official Embree project that adds AVX2 support on arm64 by treating each 8-wide AVX value as a pair of 4-wide NEON values.
(More) Differences in arm64 versus x86-64
In my previous post and in this post, I’ve covered a bunch of interesting differences and quirks that I ran into and had to take into account while porting from x86-64 to arm64.
There are, of course, far more differences that I didn’t touch on.
However, in this small section, I thought I’d list a couple more small but interesting differences that I ran into and had to think about.
arm64 and x86-64 handle float-to-int conversions slightly differently for some edge cases. Specifically, for edge values such as a uint32_t set to INF, arm64 will make a best attempt to find the nearest possible integer to convert to, which would be 4294967295. x86-64, on the other hand, treats the INF case as basically undefined behavior and defaults to just zero. In path tracing code where occasional infinite values need to be handled for things like edge cases in sampling Dirac distributions, some care needs to be taken to make sure that the renderer is understanding and processing INF values correctly on both arm64 and x86-64.
Similarly, implicit conversion from signed integers to unsigned integers can have some different behavior between the two platforms. On arm64, negative signed integers get trimmed to zero when implicitly converted to an unsigned integer; for code that must cast between signed and unsigned integers, care must be taken to make sure that all conversions are explicitly cast and that the edge case behavior on arm64 and x86-64 are accounted for.
The signedness of char is platform specific and defaults to being signed on x86-64 but defaults to being unsigned on ARM architectures [Harmon 2003], including arm64. For custom string processing functions, this may have to be taken into account.
x86-64 is always little-endian, but arm64 is a bi-endian architecture that can be either little-endian or big-endian, as set by the operating system at startup time. Most Linux flavors, including Fedora, default to little-endian on arm64, and Apple’s various operating systems all exclusively use little-endian mode on arm64 as well, so this shouldn’t be too much of a problem for most use cases. However, for software that does expect to have to run on both little and big endian systems, endianess has to be taken into account for reading/writing/handling binary data. For example, Takua has a checkpointing system that basically dumps state information from the renderer’s memory straight to disk; these checkpoint files would need to have their endianess checked and handled appropriately if I were to make Takua bi-endian. However, since I don’t expect to ever run my own hobby stuff on a big-endian system, I just have Takua check the endianess at startup right now and refuse to run if the system is big-endian.
For more details to look out for when porting x86-64 code to arm64 code on macOS specifically, Apple’s developer documentation has a whole article covering various things to consider.
Another fantastic resource for diving into arm64 assembly is Howard Oakley’s “Code in ARM Assembly” series, which covers arm64 assembly programming on Apple Silicon in extensive detail (the bottom of each article in Howard Oakley’s series contains a table of contents linking out to all of the previous articles in the series).
(More) Performance Testing
In my previous post, I included performance testing results from my initial port to arm64 Linux, running on a Raspberry Pi 4B.
Now that I have Takua Renderer up and running on a much more powerful M1 Mac Mini with 16 GB of memory, how does performance look on “big” arm64 hardware?
Last time around the machines / processors I compared were a Raspberry Pi 4B, which uses a Broadcom BCM2711 CPU with 4 Cortex-A72 cores dating back to 2015, a 2015 MacBook Air with a 2 core / 4 thread Intel Core i5-5250U CPU, and as an extremely unfair comparison point, my personal workstation with dual Intel Xeon E5-2680 CPUs from 2012 with 8 cores / 16 threads each (16 cores / 32 threads total).
The conclusion last time was that even though the Raspberry Pi 4B’s arm64 processor basically lost in terms of render time on almost every test, the Raspberry Pi 4B was actually the absolute winner by a wide margin when it came to total energy usage per render job.
This time around, since my expectation is that Apple’s M1 chip should be able to perform extremely well, I think my dual-Xeon personal workstation should absolutely be a fair competitor.
In fact, I think the comparison might actually be kind of unfair towards the dual-Xeon workstation, since the processors are from 2012 and were manufactured on the now-ancient 32 nm process, whereas the M1 is made on TSMC’s currently bleeding edge 5 nm process.
So, to give x86-64 more of a fighting chance, I’m also including a 2019 16 inch MacBook Pro with a 6 core / 8 thread Intel Core i7-9750H processor and 32 GB of memory, a.k.a. one of the fastest Intel-based laptops that Apple currently sells.
The first three test scenes are the same as last time: a standard Cornell Box, the glass teacup with ice seen in my Nested Dielectrics post, and the bedroom scene from my Shadow Terminator in Takua post.
Last time these three scenes were chosen since they fit in the 4 GB memory constraint that the Raspberry Pi 4B and the 2015 MacBook Air both have.
This time though, since the M1 Mac Mini has a much more modern 16 GB of memory, I’m including one more scene: my Scandinavian Room scene, as seen in Figure 1 of this post.
The Scandinavian Room scene is a much more realistic example of the type of complexity found in a real production render, and has much more interesting and difficult light transport.
Like before, the Cornell Box is rendered to 16 SPP using unidirectional path tracing and at 1024x1024 resolution, the Tea Cup is rendered to 16 SPP using VCM and at 1920x1080 resolution, and the Bedroom is rendered to 16 SPP using unidirectional path tracing and at 1920x1080 resolution.
Because the Scandinavian Room scene takes much longer to render due to being a much more complex scene, I’m rendered the Scandinavian Room scene to 4 SPP using unidirectional path tracing and at 1920x1080 resolution.
I left Takua Renderer’s texture caching system enabled for the Scandinavian Room scene, in order to test that the texture caching system was working correctly on arm64.
Using the texture cache could alter the performance results slightly due to disk latency to fetch texture tiles to populate the texture cache, but the texture cache hit rate after the first SPP on this scene is so close to 100% that it basically doesn’t make a difference after the first SPP, so I actually rendered the Scandinavian Room scene to 5 spp and counted the times for the last 4 and threw out timings for the first SPP.
Each test’s recorded time below is the average of the three best runs, chosen out of five runs in total for each processor.
For the M1 processor, I actually did three different types of runs, which are presented separately below.
I did one test with the native arm64 build of Takua Renderer, a second test with a version of the native arm64 build hacked to run with the M1’s hardware TSO mode enabled, and a third test running the x86-64 build on the M1 through Rosetta 2.
Also, for the Cornell Box, Tea Cup, and Bedroom scenes, I used Takua Renderer’s internal BVH implementation instead of Embree in order to match the tests from the last post, which were done before I had Embree working on arm64.
The Scandinavian Room tests use Embree as the traverser instead.
Here are the results:
CORNELL BOX
1024x1024, PT
Processor:
Wall Time:
Core-Seconds:
Broadcom BCM2711:
440.627 s
approx 1762.51 s
Intel Core i5-5250U:
272.053 s
approx 1088.21 s
Intel Xeon E5-2680 x2:
36.6183 s
approx 1139.79 s
Intel Core i7-9750H:
41.7408 s
approx 500.890 s
Apple M1 Native:
28.0611 s
approx 224.489 s
Apple M1 TSO-Enabled:
32.5621 s
approx 260.497 s
Apple M1 Rosetta 2:
42.5824 s
approx 340.658 s
TEA CUP
1920x1080, VCM
Processor:
Wall Time:
Core-Seconds:
Broadcom BCM2711:
2205.072 s
approx 8820.32 s
Intel Core i5-5250U:
2237.136 s
approx 8948.56 s
Intel Xeon E5-2680 x2:
174.872 s
approx 5593.60 s
Intel Core i7-9750H:
158.729 s
approx 1904.75 s
Apple M1 Native:
115.253 s
approx 922.021 s
Apple M1 TSO-Enabled:
128.299 s
approx 1026.39 s
Apple M1 Rosetta 2:
164.289 s
approx 1314.31 s
BEDROOM
1920x1080, PT
Processor:
Wall Time:
Core-Seconds:
Broadcom BCM2711:
5653.66 s
approx 22614.64 s
Intel Core i5-5250U:
4900.54 s
approx 19602.18 s
Intel Xeon E5-2680 x2:
310.35 s
approx 9931.52 s
Intel Core i7-9750H:
362.29 s
approx 4347.44 s
Apple M1 Native:
256.68 s
approx 2053.46 s
Apple M1 TSO-Enabled:
291.69 s
approx 2333.50 s
Apple M1 Rosetta 2:
366.01 s
approx 2928.08 s
SCANDINAVIAN ROOM
1920x1080, PT
Processor:
Wall Time:
Core-Seconds:
Intel Xeon E5-2680 x2:
119.16 s
approx 3813.18 s
Intel Core i7-9750H:
151.81 s
approx 1821.80 s
Apple M1 Native:
109.94 s
approx 879.55 s
Apple M1 TSO-Enabled:
124.95 s
approx 999.57 s
Apple M1 Rosetta 2:
153.66 s
approx 1229.32 s
The first takeaway from these new results is that Intel CPUs have advanced enormously over the past decade!
My wife’s 2019 16 inch MacBook Pro comes extremely close to matching my 2012 dual Xeon workstation’s performance on most tests and even wins on the Tea Cup scene, which is extremely impressive considering that the Intel Core i7-9750H cost around a tenth as much MSRP than the dual Intel Xeon E5-2680s would have cost new in 2012, and the Intel Core i7-9750H also uses 5 times less energy at peak than the dual Intel Xeon E5-2680s do at peak.
The real story though, is in the Apple M1 processor.
Quite simply, the Apple M1 processor completely smokes everything else on the list, often by margins that are downright stunning.
Depending on the test, the M1 processor beats the dual Xeons by anywhere between 10% and 30% in wall time and beats the 2019 MacBook Pro’s Core i7 by even more.
In terms of core-seconds, which is a measure of the overall performance of each processor core that approximates how long the render would have taken completely single-threaded, the M1’s wins are simply stunning; each of the M1’s processor cores is somewhere betweeen 4 to 6 times faster than the dual Xeons’ individual cores and between 2 to 3 times faster than the more contemporaneous Intel Core i7-9750H’s individual cores.
The even more impressive result from the M1 though, is that even running the x86-64 version of Takua Renderer using Rosetta 2’s dynamic translation system, the M1 still matches or beats the Intel Core i7-9750H.
Below is the breakdown of energy utilization for each test; the total energy used for each render is the wall clock render time multiplied by the maximum TDP of each processor to get watt-seconds, which is then divided by 3600 seconds per hour to get watt-hours.
Maximum TDP is used since Takua Renderer pushes processor utilization to 100% during each render.
As a point of comparison, I’ve also included all of the results from my previous post:
CORNELL BOX
1024x1024, PT
Processor:
Max TDP:
Total Energy Used:
Broadcom BCM2711:
4 W
0.4895 Wh
Intel Core i5-5250U:
15 W
1.1336 Wh
Intel Xeon E5-2680 x2:
260 W
2.6450 Wh
Intel Core i7-9750H:
45 W
0.5218 Wh
Apple M1 Native:
15 W
0.1169 Wh
Apple M1 TSO-Enabled:
15 W
0.1357 Wh
Apple M1 Rosetta 2:
15 W
0.1774 Wh
TEA CUP
1920x1080, VCM
Processor:
Max TDP:
Total Energy Used:
Broadcom BCM2711:
4 W
2.4500 Wh
Intel Core i5-5250U:
15 W
9.3214 Wh
Intel Xeon E5-2680 x2:
260 W
12.6297 Wh
Intel Core i7-9750H:
45 W
1.9841 Wh
Apple M1 Native:
15 W
0.4802 Wh
Apple M1 TSO-Enabled:
15 W
0.5346 Wh
Apple M1 Rosetta 2:
15 W
0.6845 Wh
BEDROOM
1920x1080, PT
Processor:
Max TDP:
Total Energy Used:
Broadcom BCM2711:
4 W
6.2819 Wh
Intel Core i5-5250U:
15 W
20.4189 Wh
Intel Xeon E5-2680 x2:
260 W
22.4142 Wh
Intel Core i7-9750H:
45 W
4.5286 Wh
Apple M1 Native:
15 W
1.0695 Wh
Apple M1 TSO-Enabled:
15 W
1.2154 Wh
Apple M1 Rosetta 2:
15 W
1.5250 Wh
SCANDINAVIAN ROOM
1920x1080, PT
Processor:
Max TDP:
Total Energy Used:
Intel Xeon E5-2680 x2:
260 W
8.606 Wh
Intel Core i7-9750H:
45 W
1.8976 Wh
Apple M1 Native:
15 W
0.4581 Wh
Apple M1 TSO-Enabled:
15 W
0.5206 Wh
Apple M1 Rosetta 2:
15 W
0.6403 Wh
Again the first takeaway from these results is just how much processor technology has improved overall in the past decade; the total energy usage by the modern Intel Core i7-9750H and Apple M1 is leaps and bounds better than the dual Xeons from 2012.
Compared to what was essentially the most powerful workstation hardware that Intel sold a little under a decade ago, a modern Intel laptop chip can now do the same work in about the same amount of time for roughly 5x less energy consumption.
The M1 though, once again entirely lives in a class of its own.
Running the native arm64 build, the M1 processor is 4 times more energy efficient than the Intel Core i7-9750H to complete the same task.
The M1’s maximum TDP is only a third of the Intel Core i7-9750H’s maximum TDP, but the actual final energy utilization is a quarter because the M1’s faster performance means that the M1 runs for much less time than the Intel Core i7-9750H.
In other words, running native code, the M1 is both faster and more energy efficient than the Intel Core i7-9750H.
This result wouldn’t be impressive if the comparison was between the M1 and some low-end, power-optimized ultra-portable Intel chip, but that’s not what the comparison is with.
The comparison is with the Intel Core i7-9750H, which is a high-end, 45 W maximum TDP part that MSRPs for $395.
In comparison, the M1 is estimated to cost about $50, and the entire M1 Mac Mini only has a 39 W TDP total at maximum load; the M1 itself is reported to have a 15 W maximum TDP.
Where the comparison between the M1 and the Intel Core i7-9750H gets even more impressive is when looking at the M1’s energy utilization running x86-64 code under Rosetta 2: the M1 is still about 3 times more energy efficient than the Intel Core i7-9750H to do the same work.
Put another way, the M1 is an arm64 processor that can run emulated x86-64 code faster than a modern native x86-64 processor that cost 5x more and uses 3x more energy can.
Another interesting observation is that the for the same work, the M1 is actually more energy efficient than the Raspberry Pi 4B as well!
In the case of the Raspberry Pi 4B comparison, while the M1’s maximum TDP is 3.75x higher than the Broadcom BCM2711’s maximum TDP, the M1 is also around 20x faster to complete each render; the M1’s massive performance uplift more than offsets the higher maximum TDP.
Another aspect of the M1 processor that I was curious enough about to test further is the M1’s big.LITTLE implementation.
The M1 has four “Firestorm” cores and four “Icestorm” cores, where Firestorm cores are high-performance but also use a ton of energy, and Icestorm cores are extremely energy-efficient but are also commensurately less performant.
I wanted to know just how much of the overall performance of the M1 was coming from the big Firestorm cores, and just how much slower the Icestorm cores are.
So, I did a simple thread scaling test where I did successive renders using 1 all the way through 8 threads.
I don’t know of a good way on the M1 to explicitly pin which kind of core a given thread runs on on; on the A12Z, the easy way to pin to the high-performance cores is to just enable hardware TSO mode since the A12Z only has hardware TSO on the high-performance cores, but this is no longer the case on the M1.
But, I figured that the underlying operating system’s thread scheduler should be smart enough to notice that Takua Renderer is a job that pushes performance limits, and schedule any available high-performance cores before using the energy-efficiency cores too.
Here are the results on the Scandinavian Room scene for native arm64, native arm64 with TSO-enabled, and x86-64 running using Rosetta 2:
M1 Native
1920x1080, PT
Threads:
Wall Time:
WT Speedup:
Core-Seconds:
CS Multiplier:
1 (1 big, 0 LITTLE)
575.6787 s
1.0x
575.6786 s
1.0x
2 (2 big, 0 LITTLE)
292.521 s
1.9679x
585.042 s
0.9839x
3 (3 big, 0 LITTLE)
197.04 s
2.9216x
591.1206 s
0.9738x
4 (4 big, 0 LITTLE)
148.9617 s
3.8646x
595.8466 s
0.9661x
5 (4 big, 1 LITTLE)
137.6307 s
4.1827x
688.1536 s
0.8365x
6 (4 big, 2 LITTLE)
128.9223 s
4.4653x
773.535 s
0.7442x
7 (4 big, 3 LITTLE)
120.496 s
4.7775x
843.4713 s
0.6825x
8 (4 big, 4 LITTLE)
109.9437 s
5.2361x
879.5476 s
0.6545x
M1 TSO-Enabled
1920x1080, PT
Threads:
Wall Time:
WT Speedup:
Core-Seconds:
CS Multiplier:
1 (1 big, 0 LITTLE)
643.9846 s
1.0x
643.9846 s
1.0x
2 (2 big, 0 LITTLE)
323.8036 s
1.9888x
647.6073 s
0.9944x
3 (3 big, 0 LITTLE)
220.4093 s
2.9217x
661.2283 s
0.9739x
4 (4 big, 0 LITTLE)
168.9733 s
3.8111x
675.8943 s
0.9527x
5 (4 big, 1 LITTLE)
153.849 s
4.1858x
769.2453 s
0.8371x
6 (4 big, 2 LITTLE)
143.7426 s
4.4801x
862.4576 s
0.7466x
7 (4 big, 3 LITTLE)
132.7233 s
4.8520x
929.0633 s
0.6931x
8 (4 big, 4 LITTLE)
124.9456 s
5.1541x
999.5683 s
0.6442x
M1 Rosetta 2
1920x1080, PT
Threads:
Wall Time:
WT Speedup:
Core-Seconds:
CS Multiplier:
1 (1 big, 0 LITTLE)
806.6843 s
1.0x
806.68433 s
1.0x
2 (2 big, 0 LITTLE)
412.186 s
1.9570x
824.372 s
0.9785x
3 (3 big, 0 LITTLE)
280.875 s
2.8720x
842.625 s
0.9573x
4 (4 big, 0 LITTLE)
207.0996 s
3.8951x
828.39966 s
0.9737x
5 (4 big, 1 LITTLE)
189.322 s
4.2609x
946.608 s
0.8521x
6 (4 big, 2 LITTLE)
175.0353 s
4.6086x
1050.2133 s
0.7681x
7 (4 big, 3 LITTLE)
166.1286 s
4.8557x
1162.9033 s
0.6936x
8 (4 big, 4 LITTLE)
153.6646 s
5.2496x
1229.3166 s
0.6562x
In the above table, WT speedup is how many times faster that given test was than the baseline single-threaded render; WT speedup is a measure of multithreading scaling efficiency.
The closer WT speedup is to the number of threads, the better the multithreading scaling efficiency; with perfect multithreading scaling efficiency, we’d expect the WT speedup number to be exactly the same as the number of threads.
The CS Multiplier value is another way to measure multithreading scaling efficiency; the closer the CS Multiplier number is to exactly 1.0, the closer each test is to achieving perfect multithreading scaling efficiency.
Since this test ran Takua Renderer in unidirectional path tracing mode, and depth-first unidirectional path tracing is largely trivially parallelizable using a simple parallel_for (okay, it’s not so simple once things like texture caching and things like learned path guiding data structures come into play, but close enough for now), my expectation for Takua Renderer is that on a system with homogeneous cores, multithreading scaling should be very close to perfect (assuming a fair scheduler in the underlying operating system).
Looking at the first four threads, which are all using the M1’s high-performance “big” Firestorm cores, close-to-perfect multithreading scaling efficiency is exactly what we see.
Adding the next four threads though, which use the M1’s low-performance energy-efficient “LITTLE” Icestorm cores, the multithreading scaling efficiency drops dramatically.
This drop in multithreading scaling efficiency is expected, since the Icestorm cores are far less performant than the Firestorm cores, but the amount that multithreading scaling efficiency drops by is what is interesting here, since that drop gives us a good estimate of just how less performant the Icestorm cores are.
The answer is that the Icestorm cores are roughly a quarter as performant as the high-performance Firestorm cores.
However, according to Apple, the Icestorm cores only use a tenth of the energy that the Firestorm cores do; a 4x performance drop for a 10x drop in energy usage is very impressive.
Conclusion to Part 2
There’s really no way to understate what a colossal achievement Apple’s M1 processor is; compared with almost every modern x86-64 processor in its class, it achieves significantly more performance for much less cost and much less energy.
The even more amazing thing to think about is that the M1 is Apple’s low end Mac processor and likely will be the slowest arm64 chip to ever power a shipping Mac (the A12Z powering the DTK is slower, but the DTK is not a shipping consumer device); future Apple Silicon chips will only be even faster.
Combined with other extremely impressive high-performance arm64 chips such as Fujistu’s A64FX supercomputer CPU, NVIDIA’s upcoming Grace GPU, Ampere’s monster 80-core Altra CPU, and Amazon’s Graviton2 CPU used in AWS, I think the future for high-end arm64 looks very bright.
That being said though, x86-64 chips aren’t exactly sitting still either.
In the comparisons above I don’t have any modern AMD Ryzen chips, entirely because I personally don’t have access to any Ryzen-based systems at the moment.
However, AMD has been making enormous advancements in both performance and energy efficiency with their Zen series of x86-64 microarchitectures, and the current Zen 3 microarchitecture thoroughly bests Intel in both performance and energy efficiency.
Intel is not sitting still either, with ambitious plans to fight AMD for the x86-64 performance crown, and I’m sure both companies have no intention of taking the rising threat from arm64 lying down.
We are currently in a very exciting period of enormous advances in modern processor technology, with multiple large, well funded, very serious players competing to outdo each other.
For the end user, no matter who comes out on top and what happens, the end result is ultimately a win- faster chips using less energy for lower prices.
Now that I have Takua Renderer fully working with parity on both x86-64 and arm64, I’m ready to take advantage of each new advancement!
Acknowledgements
For both the last post and this post, I owe Josh Filstrup an enormous debt of gratitude for proofreading, giving plenty of constructive and useful feedback and suggestions, and for being a great discussion partner over the past year on many of the topics covered in this miniseries.
Also an enormous thanks to my wife, Harmony Li, who was patient with me while I took ages with the porting work and then was patient again with me as I took even longer to get these posts written.
Harmony also helped me brainstorm through various topics and provided many useful suggestions along the way.
Finally, thanks to you, the reader, for sticking with me through these two giant blog posts!
Shawn Hickey, Matt Wojiakowski, Shipa Sharma, David Coulter, Theano Petersen, Mike Jacobs, and Michael Satran. 2021. How x86 Emulation works on ARM. In Windows on ARM. Retrieved June 26, 2021.
Saagar Jha. 2020. TSOEnabler. Retrieved June 15, 2021.
Raya and the Last Dragon’s release earlier this spring was accompanied Us Again, Disney Animation’s newest short film.
Us Again is also included on the Blu-ray for Raya and the Last Dragon, and now that the Blu-ray is out, here are some brief notes about interesting rendering details from Us Again.
Us Again is, of course, rendered entirely using Disney’s Hyperion Renderer.
I only played a small role on Us Again, pretty much entirely just support, but I thought I’d post a bit about the short because it’s such a spectacular showcase of what Hyperion is capable of when placed in Disney Animation artists’ hands.
Us Again is a stunningly beautiful film; I think it’s one of the most beautiful shorts that Disney Animation has ever made.
The short follows elderly couple Art and Dot re-finding the spark of youth in their relationship through dance.
The short is set in a bustling city and most of the short takes place in a rain storm, with raindrops flying, wet surfaces on everything, and tons of complex crowds and neon city lighting reflecting everywhere.
From a rendering perspective, this can be a preposterously difficult setting to render; there are tons of lights stressing any kind of light sampling strategy, there are tons of specular surfaces and reflections generating difficult to sample light transport, the city setting means the geometric complexity is through the roof, the face paced dance sequences and rainfall means there is high motion blur everywhere, and so on and so forth.
A little under ten years ago, I was an intern at Pixar during the production of The Blue Umbrella, which also has a rainy urban setting, and I got a close up view of how that short was at the time one of the hardest things Pixar had ever rendered.
Us Again has even more complex challenges on top of what was in The Blue Umbrella, so I was really worried that we would run into major difficulties rendering Us Again.
I was really pleasantly surprised when… lighting and rendering Us Again went really smoothly and basically no major problems or difficulties emerged at all!
Rendering technology generally has advanced enormously in the past ten years, and by fortunate coincidence Hyperion just happens to have a lot of specific capabilities that are particularly well suited to the rendering challenges in Us Again.
Us Again used essentially the same version of Hyperion that was used for Frozen 2, with one notable modification.
Motion blur on Us Again took some special care to handle because of all of the rain; fast-falling raindrops with a wider shutter angle blurs out into the familiar long streaks that are usually seen in “movie rain”.
Because the motion blurred streaks for rain were so long in screen space, the streaks would tend to bend whenever the camera was under high motion too, sort of like how fast-spinning propellor blades end up looking weird on rolling shutter cameras.
Hyperion already allows for different objects in the same scene and same render to effectively be rendered with different shutter angles; to fix the look of the rain streaks on Us Again, all the team had to add was the ability to decouple camera motion blur from object motion blur.
For pretty much everything else on Us Again, our existing solutions in Hyperion just worked.
Us Again’s urban setting represents a worst-case complexity scenario for light selection and light sampling.
Because Us Again is set in a city, every shot in the short has a gazillion lights present spread across a huge region of space, and the finale of the short takes place on a boardwalk amusement park pier1 with a ferris wheel and other rides covered in animated light bulbs.
These types of lighting scenarios through the sheer number of lights present combined with the complex occlusion can sometimes be enough to overwhelm light-BVH based many-lights sampling strategies [Estevez and Kulla 2018], and without a many-lights sampling strategy that can handle these cases well, in the worse case falling back to laborious manual grouping and culling of lights may be the only option [Vavilala 2019].
However, Hyperion’s “cache points” many-lights sampling system was developed from the very beginning to handle millions of lights with complex occlusion in vast cityscapes, because this was the exact type of setting that was found throughout Big Hero 6[Burley et al. 2018].
For Us Again, Hyperion’s cache points system handled all of the highest lighting complexity scenes (such as the ferris wheel on the pier) with millions of light sources with no problem at all; our lighters simply opened the scenes, lit like usual, hit render, and everything just worked efficiently with zero additional optimization work required [Li et al. 2024].
In a similar vein, because Us Again is set in a rain storm, every asset needed to have both wet and dry variants with custom blending between the two, which would be challenging to author if wet and dry looks had to be authored separately.
However, thanks to Disney Animation’s layer stack shading model with sparse overrides [Burley 2012, Burley 2018], adding a wet look to every shader was as simple as just sticking on an additional wet layer, driven with whatever masks artists wanted.
Finally, one of the things I love the most visually about Us Again is just the sheer amount of detail and richness there is in everything.
When watching the short, pay attention to things like the fuzz on Dot’s sweater, or the little splashes happening everywhere as rain drops land, or the streaks of water running down Art and Dot’s faces and clothes.
I think ten years ago this short would have been extraordinarily difficult (possibly borderline impossible) for the studio to make, but thanks to a decade of continuous relentless improvement in our filmmaking technology and craft, making Us Again went off without any major hitches and turned out beautifully!
Here are some frames from Us Again from the Blu-ray, presented in random order as usual.
I really recommend seeing Us Again in motion though; the stills here really don’t do the amazing choreography and animation justice.
Get Us Again with a copy of Raya and the Last Dragon or watch it on on Disney+; either way, go watch it on the biggest screen you can find!
All images in this post are courtesy of and the property of Walt Disney Animation Studios.
Brent Burley, David Adler, Matt Jen-Yuan Chiang, Hank Driskill, Ralf Habel, Patrick Kelly, Peter Kutz, Yining Karl Li, and Daniel Teece. 2018. The Design and Evolution of Disney’s Hyperion Renderer. ACM Transactions on Graphics 37, 3 (Jul. 2018), Article 33.
1 If you pay close attention, you may notice that the pier amusement park in Us Again is a nod to the old Paradise Pier area at Disney’s California Adventure, complete with the same entrance sign!
keyboard_return
For almost its entire existence my hobby renderer, Takua Renderer, has built and run on Mac, Windows, and Linux on x86-64.
I maintain Takua on all three major desktop operating systems because I routinely run and use all three operating systems, and I’ve found that building with different compilers on different platforms is a good way for making sure that I don’t have code that is actually wrong but just happens to work because of the implementation quirks of a particular compiler and / or platform.
As of last year, Takua Renderer now also runs on 64-bit ARM, for both Linux and Mac!
64-bit ARM is often called either aarch64 or arm64; these two terms are interchangeable and mean the same thing (aarch64 is the official name for 64-bit ARM and is what Linux tends to use, while arm64 is the name that Apple and Microsoft’s tools tend to use).
For the sake of consistency, I’ll use the term arm64.
This post is the first of a two-part writeup of the process I undertook to port Takua Renderer to run on arm64, along with interesting stuff that I learned along the way.
In this first part, I’ll write about motivation and the initial port I undertook in the spring to arm64 Linux (specifically Fedora).
I’ll also write about how arm64 and x86-64’s memory ordering guarantees differ and what that means for lock-free code, and I’ll also do some deeper dives into topics such as floating point differences between different processors and a case study examining how code compiles to x86-64 versus to arm64.
In the second part, I’ll write about porting to arm64-based Apple Silicon Macs and I’ll also write about getting Embree up and running on ARM, creating Universal Binaries, and some other miscellaneous topics.
Motivation
So first, a bit of a preamble: why port to arm64 at all?
Today, basically most, if not all, of the animation/VFX industry renders on x86-64 machines (and a vast majority of those machines are likely running Linux), so pretty much all contemporary production rendering development happens on x86-64.
However, this has not always been true!
A long long time ago, much of the computer graphics world was based on MIPS hardware running SGI’s IRIX Unix variant; in the early 2000s, as SGI’s custom hardware began to fall behind the performance-per-dollar, performance-per-watt, and even absolute performance that commodity x86-based machines could offer, the graphics world undertook a massive migration to the current x86 world that we live in today.
Apple undertook a massive migration from PowerPC to x86 in the mid/late 2000s for similar reasons.
At this point, an ocean of text has been written about why it is that x86 (and by (literal) extension x86-64) became the dominant ISA in desktop computing and in the server space.
One common theory that I like is that x86’s dominance was a classic example of disruptive innovation from the low end.
A super short summary of disruptive innovation from the low end is that sometimes, a new player enters an existing market with a product that is much less capable but also much cheaper than existing competing products.
By being so much cheaper, the new product can generate a new, larger market that existing competing products can’t access due to their higher cost or different set of requirements or whatever.
As a result, the new product gets massive investment since the new product is the only thing that can capture this new larger market, and in turn this massive influx of investment allows the new player to iterate faster and rapidly grow its product in capabilities until the new player becomes capable of overtaking the old market as well.
This theory maps well to x86; x86-based desktop PCs started off being much cheaper but also much less capable than specialized hardware such as SGI machines, but the investment that poured into the desktop PC space allowed x86 chips to rapidly grow in absolute performance capability until they were able to overtake specialized hardware in basically every comparable metric.
At that point, moving to x86 became a no-brainer for many industries, including the computer graphics realm.
I think that ARM is following the same disruptive innovation path that x86 did, only this time the starting “low end” point is smartphones and tablets, which is an even lower starting point than desktop PCs were.
More importantly, I think we’re now at a tipping point for ARM.
For many years now, ARM chips have offered better performance-per-dollar and performance-per-watt than any x86-64 chip from Intel or AMD, and the point where arm64 chips can overtake x86-64 chips in absolute performance seems plausibly within sight over the next few years.
Notably, Amazon’s in-house Graviton2 arm64 CPU and Apple’s M1 arm64-based Apple Silicon chip are both already highly competitive in absolute performance terms with high end consumer x86-64 CPUs, while consuming less power and costing less.
Actually, I think that this trend should have been obvious to anyone paying attention to Apple’s A-series chips since the A9 chip was released in 2015.
In cases of disruptive innovation from the low end, the outer edge of the absolute high end is often the last place where the disruption reaches.
One of the interesting things about the high-end rendering field is that high-end rendering is one of a relatively small handful of applications that sits at the absolute outer edge of high end compute performance.
All of the major animation and VFX studios have render farms (either on-premises or in the cloud) with core counts somewhere in the tens of thousands of cores; these render farms have more similarities with supercomputers than they do with a regular consumer desktop or laptop.
I don’t know that anyone has actually tried this, but my guess is that if someone benchmarked any major animation or VFX studio’s render farm using the LINPACK supercomputer benchmark, the score would sit very respectably somewhere in the upper half of the TOP500 supercomputer list.
With the above in mind, the fact that the fastest supercomputer in the world is now an arm64-based system should be an interesting indicator of where ARM is now in the process of catching up to x86-64 and how seriously all of us in high-end computer graphics should be when contemplating the possibility of an ARM-based future.
So all of the above brings me to why I undertook porting Takua to arm64.
The reason is because I think we can now plausibly see a potential near future in which the fastest, most efficient, and most cost effective chips in the world are based on arm64 instead of x86-64, and the moment this potential future becomes reality, high-performance software that hasn’t already made the jump will face growing pressure to port to arm64.
With Apple’s in-progress shift to arm64-based Apple Silicon Macs, we may already be at this point.
I can’t speak for any animation or VFX studio in particular; everything I have written here is purely personal opinion and personal conjecture, but I’d like to be ready in the event that a move to arm64 becomes something we have to face as an industry, and what better way is there to prepare than to try with my own hobby renderer first!
Also, for several years now I’ve thought that Apple eventually moving Macs to arm64 was obvious given the progress the A-series Apple chips were making, and since macOS is my primary personal daily use platform, I figured I’d have to port Takua to arm64 eventually anyway.
Porting to arm64 Linux
I actually first attempted an ARM port of Takua several years ago, when Fedora 27 became the first version of Fedora to support arm64 single-board computers (SBCs) such as the Raspberry Pi 3B or the Pine A64.
I’ve been a big fan of the Raspberry Pi basically since the original first came out, and the thought of porting Takua to run on a Raspberry Pi as an experiment has been with me basically since 2012.
However, Takua is written very much with 64-bit in mind, and the first two generations of Raspberry Pis only had 32-bit ARMv7 processors.
I actually backed the original Pine A64 on Kickstarter in 2015 precisely because it was one of the very first 64-bit ARMv8 boards on the market, and if I remember correctly, I also ordered the Raspberry Pi 3B the week it was announced in 2016 because it was the first 64-bit ARMv8 Raspberry Pi.
However, my Pine A64 and Raspberry Pi 3B mostly just sat around not doing much because I was working on a bunch of other stuff, but that actually wound up working out because by the time I got back around to tinkering with SBCs in late 2017, Fedora 27 had just been released.
Thanks to a ton of work from Peter Robinson at Red Hat, Fedora 27 added native arm64 support that basically worked out-of-the-box on both the Raspberry Pi 3B and the Pine A64, which was ideal for me since my Linux distribution of choice for personal hobby projects is Fedora.
Since I already had Takua building and running on Fedora on x86-64, being able to use Fedora as the target distribution for arm64 as well meant that I could eliminate different compiler and system library versions as a variable factor; I “just” had to move everything in my Fedora x86-64 build over to Fedora arm64.
However, back in 2017, I found that a lot of the foundational libraries that Takua depends on just weren’t quite ready on arm64 yet.
The problem usually wasn’t with the actual source code itself, since anything written in pure C++ without any intrinsics or inline assembly should just compile directly on any platform with a supported compiler; instead, the problem was usually just in build scripts not knowing how to handle small differences in where system libraries were located or stuff like that.
At the time I was focused on other stuff, so I didn’t try particularly hard to diagnose and work around the problems I ran into; I kind of just shrugged and put it all aside to revisit some other day.
Fast forward to early 2020, when rumors started circulating of a potential macOS transition to 64-bit ARM.
As the rumors grew, I figured that this was a good time to return to porting Takua to arm64 Fedora in preparation for if a macOS transition actually happened.
I had also recently bought a Raspberry Pi 4B with 4 GB of RAM; the 4 GB of RAM made actually building and running complex code on-device a lot easier than with the Raspberry Pi 3B/3B+’s 1 GB of RAM.
By this point, the arm64 build support level for Takua’s dependencies had improved dramatically.
I think that as arm64 devices like the iPhone and iPad Pro have gotten more and more powerful processors over the last few years and enabled more and more advanced and complex iOS / iPadOS apps (and similarly with Android devices and Android apps), more and more open source libraries have seen adoption on ARM-based platforms and have seen ARM support improve as a result.
Almost everything just built and worked out-of-the-box on arm64, including (to my enormous surprise) Intel’s TBB library!
I had assumed that TBB would be x86-64-only since TBB is an Intel project, but it turns out that over the years, the community has contributed support for ARMv7 and arm64 and even PowerPC to TBB.
The only library that didn’t work out-of-the-box or with minor changes was Embree, which relies heavily on SSE and AVX intrinsics and has small amounts of inline x86-64 assembly.
To get things up and running initially, I just disabled Takua’s Embree-based traversal backend and fell back to my own custom BVH traversal backend.
My own custom BVH traversal backend isn’t nearly as fast as Embree and is instead meant to serves as a reference implementation and fallback for when Embree isn’t available, but for the time being since the goal was just to get Takua working at all, losing performance due to not having Embree was fine.
As you can see by the “Traverser: Embree” label in Takua Renderer’s UI in Figure 1, I later got Embree up and running on arm64 using Syoyo Fujita’s embree-aarch64 port, but I’ll write more about that in the next post.
To be honest, the biggest challenge with getting everything compiled and running was just the amount of patience that was required.
I never seem to be able to get cross-compilation for a different architecture right because I always forget something, so instead of cross-compiling for arm64 from my nice big powerful x86-64 Fedora workstation, I just compiled for arm64 directly on the Raspberry Pi 4B.
While the Raspberry Pi 4B is much faster than the Raspberry Pi 3B, it’s still nowhere near as fast as a big fancy dual-Xeon workstation, so some libraries took forever to compile locally (especially Boost, which I wish I didn’t have to have a dependency on, but I have to since OpenVDB depends on Boost).
Overall getting a working build of Takua up and running on arm64 was very fast; from deciding to undertake the port to getting a first image back took only about a day’s worth of work, and most of that time was just waiting for stuff to compile.
However, getting code to build is a completely different question from getting code to run correctly (unless you’re using one of those fancy proof-solver languages I guess).
The first test renders I did with Takua on arm64 Fedora looked fine to my eye, but when I diff’d them against reference images rendered on x86-64, I found some subtle differences; the source of these differences took me a good amount of digging to understand!
Chasing this problem down led down some interesting rabbit holes exploring important differences between x86-64 and arm64 that need to be considered when porting code between the two platforms; just because code is written in portable C++ does not necessarily mean that it is always actually as portable as one might think!
Floating Point Consistency (or lack thereof) on Different Systems
Takua has two different types of image comparison based regression tests: the first type of test renders out to high samples-per-pixel numbers and does comparisons with near-converged images, while the second type of test renders out and does comparisons using a single sample-per-pixel.
The reason for these two different types of tests is because of how difficult getting floating point calculations to match across different compilers / platforms / processors is.
Takua’s single-sample-per-pixel tests are only meant to catch regressions on the same compiler / platform / processor, while Takua’s longer tests are meant to test overall correctness of converged renders.
Because of differences in how floating point operations come out on different compilers / platforms / processors, Takua’s convergence tests don’t require an exact match; instead, the tests use small, predefined difference thresholds that comparisons must stay within to pass.
The difference thresholds are basically completely ad-hoc; I picked them to be at a level where I can’t perceive any difference when flipping between the images, since I put together my testing system before image differencing systems that formally factor in perception [Andersson et al. 2020] were published.
A large part of the differences between Takua’s test results on x86-64 versus arm64 come from these problems with floating point reproducibility across different systems.
Because of how commonplace this issue is and how often this issue is misunderstood by programmers who haven’t had to deal with it, I want to spend a few paragraphs talking about floating point numbers.
A lot of programmers that don’t have to routinely deal with floating point calculations might not realize that even though floating point numbers are standardized through the IEEE754 standard, in practice reproducibility is not at all guaranteed when carrying out the same set of floating point calculations using different compilers / platforms / processors!
In fact, starting with the same C++ floating point code, determinism is only really guaranteed for successive runs using binaries generated using the same compiler, with the same optimizations enabled, on the same processor family; sometimes running on the same operating system is also a requirement for guaranteed determinism.
There are three main reasons [Kreinin 2008] why reproducing exactly the same results from the same set of floating point calculations across different systems is so inconsistent: compiler optimizations, processor implementation details, and different implementations of built-in “complex” functions like sine and cosine .
The first reason above is pretty easy to understand: operations like addition and multiplication are commutative, meaning they can be done in any order, and often a compiler in an optimization pass may choose to reorder commutative math operations.
However, as anyone who has dealt extensively with floating point numbers knows, due to how floating point numbers are represented [Goldberg 1991] the commutative and associative properties of addition and multiplication do not actually hold true for floating point numbers; not even for IEEE754 floating point numbers!
Sometimes reordering floating point math is expressly permitted by the language, and sometimes doing this is not actually allowed by the language but happens anyway in the compiler because the user has specified flags like -ffast-math, which tells the compiler that it is allowed to sacrifice strict IEEE754 and language math requirements in exchange for additional optimization opportunities.
Sometimes the compiler can just have implementation bugs too; here is an example that I found on the llvm-dev mailing lists describing a bug with loop vectorization that impacts floating point consistency!
The end result of all of the above is that the same floating point source code can produce subtly different results depending on which compiler is used and which compiler optimizations are enabled within that compiler.
Also, while some compiler optimization passes operate purely on the AST built from the parser or operate purely on the compiler’s intermediate representation, there can also be optimization passes that take into account the underlying target instruction set and choose to carry out different optimizations depending on the what’s available in the target processor architecture.
These architecture-specific optimizations mean that even the same floating point source code compiled using the same compiler can still produce different results on different processor architectures!
Architecture-specific optimizations are one reason why floating point results on x86-64 versus arm64 can be subtly different.
Also, another fun fact: the C++ specification doesn’t actually specify a binary representation for floating point numbers, so in principle a C++ compiler could outright ignore IEEE754 and use something else entirely, although in practice this is basically never the case since all modern compilers like GCC, Clang, and MSVC use IEEE754 floats.
The second reason floating point math is so hard to reproduce exactly across different systems is in how floating point math is implemented in the processor itself.
Differences at this level is a huge source of floating point differences between x86-64 and arm64.
In both x86-64 and arm64, at the assembly level individual arithmetic instructions such as add, subtract, multiple, divide, etc all adhere strictly to the IEEE754 standard.
However, the IEEE754 standard is itself… surprisingly loosely specified in some areas!
For example, the IEEE754 standard specifies that intermediate results should be as precise as possible, but this means that two different implementations of a floating point addition instructions both adhering to IEEE754 can actually produce different results for the same input if they use different levels of increased precision internally.
Here’s a bit of a deprecated example that is still useful to know for historical reasons: everyone knows that an IEEE754 floating point number is 32 bits, but older 32-bit x86 specifies that internal calculations be done using 80-bit precision, which is a holdover from the Intel 8087 math coprocessor.
Every x86 (and by extension x86-64) processor when using x87 FPU instructions actually does floating point math using 80 bit internal precision and then rounds back down to 32 bit floats in hardware; the 80 bit internal representation is known as the x86 extended precision format.
But even within the same x86 processor, we can still get difference floating point results depending on if the compiler has output x87 FPU instructions or SSE instructions; SSE stays within 32 bits at all times, which means SSE and x87 on the same processor doing the same floating point math isn’t guaranteed to produce the exact same answer.
Of course, modern x86-64 generally uses SSE for floating point math instead of x87, but different amounts of precision truncation can still happen depending on what order values are loaded into SSE registers and back into other non-SSE registers.
Furthermore, SSE is sufficiently under-specified that the actual implementation details can differ, which is why the same SSE floating point instructions can produce different results on Intel versus AMD processors.
Similarly, the ARM architecture doesn’t actually specify a particular FPU implementation at all; the internals of the FPU are left up to each processor designer; for example, the VFP/NEON floating point units that ship on the Raspberry Pi 4B’s Cortex-A72-based CPU use up to 64 bits of internal precision [Johnston 2020].
So, while the x87, SSE on Intel, SSE on AMD, and VFP/NEON FPU implementations are IEEE754-compliant, because of their internal maximum precision differences they can still all produce different results from each other.
There are many more examples of areas where IEEE754 leaves in wiggle room for different implementations to do different things [Obiltschnig 2006], and in practice different CPUs do use this wiggle room to do things differently from each other.
For example, this wiggle room is why for floating point operations at the extreme ends of the IEEE754 float range, Intel’s x86-64 versus AMD’s x86-64 versus arm64 can produce results with minor differences from each other in the end of the mantissa.
Finally, the third reason floating point math can vary across different systems is because of transcendental functions such as sine and cosine.
Transcendental functions like sine and cosine have exact, precise mathematical definitions, but unfortunately these precise mathematical definitions can’t be implemented exactly in hardware.
Think back to high school trigonometry; the exact answer for a given input to functions like sine and cosine have to be determined using a Taylor series, but actually implementing a Taylor series in hardware is not at all practical nor performant.
Instead, modern processors typically use some form of a CORDIC algorithm to approximate functions like sine and cosine, often to reasonably high levels of accuracy.
However, the level of precision to which any given processor approximates sine and cosine is completely unspecified by either IEEE754 or any language standard; as a result, these approximations can and do vary widely between different hardware implementations on different processors!
However, how much this reason actually matters in practice is complicated and compiler/language dependent.
As an example using cosine, the standard library could choose to implement cosine in software using a variety of different methods, or the standard library could choose to just pass through to the hardware cosine implementation.
To illustrate how much the actual execution path depends on the compiler: I originally wanted to include a simple small example using cosine that you, the reader, could go and compile and run yourself on an x86-64 machine and then on an arm64 machine to see the difference, but I wound up having so much difficulty convincing different compilers on different platforms to actually compile the cosine function (even using intrinsics like __builtin_cos!) down to a hardware instruction reliably that I wound up having to abandon the idea.
One of the things that makes all of the above even more difficult to reason about is that which specific factors are applicable at any given moment depends heavily on what the compiler is doing, what compiler flags are in use, and what the compiler’s defaults are.
Actually getting floating point determinism across different systems is a notoriously difficult problem [Fiedler 2010] that volumes of stuff has been written about!
On top of that, while in principle getting floating point code to produce consistent results across many different systems is possible (hard, but possible) by disabling compiler optimizations and by relying entirely on software implementations of floating point operations to ensure strict, identical IEEE754 compliance on all systems, actually doing all of the above comes with major trade-offs.
The biggest trade-off is simply performance: all of the changes necessary to make floating point code consistent across different systems (and especially across different processor architectures like x86-64 versus arm64) also likely will make the floating point considerably slower too.
All of the above reasons mean that modern usage of floating point code basically falls into three categories.
The first category is: just don’t use floating point code at all.
Included in this first category are applications that require absolute precision and absolute consistency and determinism across all implementations; examples are banking and financial industry code, which tend to store monetary values entirely using only integers.
The second category are applications that absolutely must use floats but also must ensure absolute consistency; a good example of applications in this category are high-end scientific simulations that run on supercomputers.
For applications in this second category, the difficult work and the performance sacrifices that have to be made in favor of consistency are absolutely worthwhile.
Also, tools do exist that can help with ensuring floating point consistency; for example, Herbie is a tool that can detect potentially inaccurate floating point expressions and suggest more accurate replacements.
The last category are applications where the requirement for consistency is not necessarily absolute, and the requirement for performance may weigh heavier.
This is the space that things like game engines and renderers and stuff live in, and here the trade-offs become more nuanced and situation-dependent.
A single-player game may choose absolute performance over any kind of cross-platform guaranteed floating point consistency, whereas a multi-player multi-platform game may choose to sacrifice some performance in order to guarantee that physics and gameplay calculations produce the same result for all players regardless of platform.
Takua Renderer lives squarely in the third category, and historically the point in the trade-off space that I’ve chosen for Takua Renderer is to favor performance over cross-platform floating point consistency.
I have a couple of reasons for choosing this trade-off, some of which are good and some of which are… just laziness, I guess!
As a hobby renderer, I’ve never had shipping Takua as a public release in any form in mind, and so consistency across many platforms has never really mattered to me.
I know exactly which systems Takua will be run on, because I’m the only one running Takua on anything, and to me having Takua run slightly faster at the cost of minor noise differences on different platforms seems worthwhile.
As long as Takua is converging to the correct image, I’m happy, and for my purposes, I consider converged images that are perceptually indistinguishable when compared with a known correct reference to also be correct.
I do keep determinism within the same platform as a major priority though, since determinism within each platform is important for being able to reliably reproduce bugs and is important for being able to reason about what’s going on in the renderer.
Here is a concrete example of the noise differences I get on x86-64 versus on arm64.
This scene is the iced tea scene I originally created for my Nested Dielectrics post; I picked this scene for this comparison purely because it is has a small memory footprint and therefore fits in the relatively constrained 4 GB memory footprint of my Raspberry Pi 4B, while also being slightly more interesting than a Cornell Box.
Here is a comparison of a single sample-per-pixel render using bidirectional path tracing on a dual-socket Xeon E5-2680 x86-64 system versus on a Raspberry Pi 4B with a Cortex-A72 based arm64 processor.
The scene actually appears somewhat noisier than it normally would be coming out of Takua renderer because for this demonstration, I disabled low-discrepancy sampling and had the renderer fall back to purely random PCG-based sample sequences, with the goal of trying to produce more noticeable noise differences:
Figure 2: A single-spp render demonstrating noise pattern differences between x86-64 (left) versus arm64 (right). Differences are most noticeable on rim of the cup, especially on the left near the handle. For a full screen comparison, click here.
The noise differences are actually relatively minimal!
The most noticeable noise differences are on the rim of the cup; note the left of the rim near the handle.
Since the noise differences can be fairly difficult to see in the full render on a small screen, here is a 2x zoomed-in crop:
Figure 3: A zoomed-in crop of Figure 2 showing noise pattern differences between x86-64 (left) versus arm64 (right). For a full screen comparison, click here.
The differences are still kind of hard to see even in the zoomed-in crop!
So, here’s the absolute difference between the x86-64 and arm64 renders, created by just subtracting the images from each other and taking the absolute value of the difference at each pixel.
Black pixels indicate pixels where the absolute difference is zero (or at least, so close to zero so as to be completely imperceptible).
Brighter pixels indicate greater differences between the x86-64 and arm64 renders; from where the bright pixels are, we can see that most of the differences occur on the rim of the cup, on ice cubes in the cup, and in random places mostly in the caustics cast by the cup.
There’s also a faint horizontal line of small differences across the background; that area lines up with where the seamless white cyclorama backdrop starts to curve upwards:
Understanding why the areas with the highest differences are where they are requires thinking about how light transport is functioning in this specific scene and how differences in floating point calculations impact that light transport.
This scene is lit fairly simply; the only light sources are two rect lights and a skydome.
Basically everything is illuminated through direct lighting, meaning that for most areas of the scene, a ray starting from the camera is directly hitting the diffuse background cyclorama and then sampling a light source, and a ray starting from the light is directly hitting the diffuse background cyclorama and then immediately sampling the camera lens.
So, even with bidirectional path tracing, the total path lengths for a lot of the scene is just two path segments, or one bounce.
That’s not a whole lot of path for differences in floating point calculations to accumulate during.
On the flip side, most of the areas with the greatest differences are areas where a lot of paths pass through the glass tea cup.
For paths that go through the glass tea cup, the path lengths can be very long, especially if a path gets caught in total internal reflection within the glass walls of the cup.
As the path lengths get longer, the floating point calculation differences at each bounce accumulate until the entire path begins to diverge significantly between the x86-64 and arm64 versions of the render.
Fortunately, these differences basically eventually “integrate out” thanks to the magic of Monte Carlo integration; by the time the renders are near converged, the x86-64 and arm64 results are basically perceptually indistinguishable from each other:
Figure 5: The same cup scene from Figure 1, but now much closer to convergence (2048 spp), rendered using x86-64 (left) and arm64 (right). Note how differences between the x86-64 and arm64 renders are now basically imperceptible to the eye; these are in fact two different images! For a full screen comparison, click here.
Below is the absolute difference between the two images above.
To the naked eye the absolute difference image looks completely black, because the differences between the two images are so small that they’re basically below the threshold of normal perception.
So, to confirm that there are in fact differences, I’ve also included below a version of the absolute difference exposed up 10 stops, or made 1024 times brighter.
Much like in the single spp renders in Figure 1, the areas of greatest difference are in the areas where the path lengths are the longest, which in this scene are areas where paths refract through the glass cup, the tea, and the ice cubes.
Just, the differences between individual paths for the same sample across x86-64 and arm64 become tiny to the point of insignificance once averaged across 2048 samples-per-pixel:
Figure 6: Left: Absolute difference between the x86-64 and arm64 renders from Figure 2. Right: Since the absolute difference image basically looks completely black to the eye, I've also included a version of the absolute difference exposed up 10 stops (made 1024 times brighter) to make the differences more visible. For a full screen comparison, click here.
For many extremely precise scientific applications, the level of differences above would still likely be unacceptable, but for our purposes in just making pretty pictures, I’ll call this good enough!
In fact, many rendering teams only target perceptually indistinguishable for the purposes of calling things deterministic enough, as opposed to aiming for absolute binary-level determinism; great examples include Pixar’s RenderMan XPU, Disney Animation’s Hyperion, and DreamWorks Animation’s MoonRay.
Eventually maybe I’ll get around to putting more work into trying to get Takua Renderer’s per-path results to be completely consistent even across different systems and processor architectures and compilers, but for the time being I’m fine with keeping that goal as a fairly low priority relative to everything else I want to work on, because as you can see, once the renders are converged, the difference doesn’t really matter!
Floating point calculations accounted for most of the differences I was finding when comparing renders on x86-64 versus renders on arm64, but only most.
The remaining source of differences turned out… to be an actual bug!
Weak Memory Ordering in arm64 and Atomic Bugs in Takua
Multithreaded programming with atomics and locks has a reputation for being one of the relatively more challenging skills for programmers to master, and for good reason.
Since different processor architectures often have different semantics and guarantees and rules around multithreading-related things like memory reordering, porting between different architectures is often a great way to expose subtle multithreading bugs.
The remaining source of major differences between the x86-64 and arm64 renders I was getting turned out to be caused by a memory reordering-related bug in some old multithreading code that I wrote a long time ago and forgot about.
In addition to outputing the main render, Takua Renderer is also able to generate some additional render outputs, including some useful diagnostic images.
One of the diagnostic render outputs is a sample heatmap, which shows how many pixel samples were used for each pixel in the image.
I originally added the sample heatmap render output to Takua when I was implementing adaptive sampling, and since then the sample heatmap render output has been a useful tool for understanding how much time Takua is spending on different parts of the image.
One of the other things the sample heatmap render output has served as though is as a simple sanity check that Takua’s multithreaded work dispatching system is functioning correctly.
For a render where the adaptive sampler is disabled, the sample heatmap should contain exactly the same value for every single pixel in the entire image, since without adaptive sampling, every pixel is just being rendered to the target samples-per-pixel of the entire render.
So, in some of my tests, I have the renderer scripted to always output the sample heatmap, and the test system checks that the sample heatmap is completely uniform after the render as a sanity check to make sure that the renderer has rendered everything that it was supposed to.
To my surprise, sometimes on arm64, a test would fail because the sample heatmap for a render without adaptive sampling would come back as nonuniform!
Specifically, the sample heatmap would come back indicating that some pixels had received one fewer sample than the total target sample-per-pixel count across the whole render.
These pixels were always in square blocks corresponding to a specific tile, or multithreaded work dispatch unit.
The specific bug was in how Takua Renderer dispatches rendering work to each thread; to provide the relevant context and explain what I mean by a “tile”, I’ll first have to quickly describe how Takua Renderer is multithreaded.
In university computer graphics courses, path tracing is often taught as being trivially simple to parallelize: since a path tracer traces individual paths in a depth-first fashion, individual paths don’t have dependencies on other paths, so just assign each path that has to be traced to a separate thread.
The easiest way to implement this simple parallelization scheme is to just run a parallel_for loop over all of the paths that need to be traced for a given set of samples, and to just repeat this for each set of samples until the render is complete.
However, in reality, parallelizing a modern production-grade path tracing renderer is often not as simple as the classic “embarrassingly parallel” approach.
Modern advanced path tracers often are written to take into account factors such as cache coherency, memory access patterns and memory locality, NUMA awareness, optimal SIMD utilization, and more.
Also, advanced path tracers often make use of various complex data structures such as out-of-core texture caches, photon maps, path guiding trees, and more.
Making sure that these data structures can be built, updated, and accessed on-the-fly by multiple threads simultaneously and efficiently often introduces complex lock-free data structure design problems.
On top of that, path tracers that use a wavefront or breadth-first architecture instead of a depth-first approach are far from trivial to parallelize, since various sorting and batching operations and synchronization points need to be accounted for.
Even for relatively straightforward depth-first architectures like the one Takua has used for the past six years, the direct parallel_for approach can be improved upon in some simple ways.
Before progressive rendering became the standard modern approach, many renderers used an approach called “bucket” rendering [Geupel 2018], where the image plane was divided up into a bunch of small tiles, or buckets.
Each thread would be assigned a single bucket, and each thread would be responsible for rendering that bucket to completion before being assigned another bucket.
For offline, non-interactive rendering, bucket rendering often ends up being faster than just a simple parallel_for because bucket rendering allows for a higher degree of memory access coherency and cache coherency within each thread since each thread is always working in roughly the same area of space (at least for the first few bounces).
Even with progressive rendering as the standard approach for renderers running in an interactive mode today, many (if not most) renderers still use a bucketed approach when dispatched to a renderfarm today.
For CPU path tracers today, the number of pixels that need to be rendered for a typical image is much much larger than the number of hardware threads available on the CPU.
As a result, the basic locality idea that bucket rendering utilizes also ends up being applicable to progressive, interactive rendering in CPU path tracers (for GPU path tracing though, the GPU’s completely different, wavefront-based SIMT threading model means a bit of a different approach is necessary).
RenderMan, Arnold, and Vray in interactive progressive mode all still render pixels in a bucket-like order, although instead of having each thread render all samples-per-pixel to completion in each bucket all at once, each thread just renders a single sample-per-pixel for each bucket and then the renderer loops over the entire image plane for each sample-per-pixel number.
To differentiate using buckets in a progressive mode from using buckets in a batch mode, I will refer to buckets in progressive mode as “tiles” for the rest of this post.
Takua Renderer also supports using a tiled approach for assigning work to individual threads.
At renderer startup, Takua precalculates a work assignment order, which can be in a tiled fashion, or can use a more naive parallel_for approach; the tiled mode is the default.
When using a tiled work assignment order, the specific order of tiles supports several different options; the default is a spiral starting from the center of the image.
Here’s a short screen recording demonstrating what this tiling work assignment looks like:
Figure 7: A short video showing Takua Renderer's tile assignment system running in spiral mode; each red outlined square represents a single tile. This video was captured on an arm64 M1 Mac Mini running macOS Big Sur instead of on a Raspberry Pi 4B because trying to screen record on a Raspberry Pi 4B while also running the renderer was not a good time. To see this video in a full window, click here.
As threads free up, the work assignment system hands each free thread a tile to render; each thread then renders a single sample-per-pixel for every pixel in its assigned tile and then goes back to the work assignment system to request more work.
Once the number of remaining tiles for the current samples-per-pixel number drops below the number of available threads, the work assignment system starts allowing multiple threads to team up on a single tile.
In general, the additional cache coherency and more localizes memory access patterns from using a tiled approach gives Takua Renderer a minimum 3% speed improvement compared to using a naive parallel_for to assign work to each thread; sometimes the speed improvement can be even higher if the scene is heavily dependent on things like texture cache access or reading from a photon map.
The reason the work assignment system actually hands out tiles one by one upon request instead of just running a parallel_for loop over all of the tiles is because using something like tbb::parallel_for means that the tiles won’t actually be rendered in the correct specified order.
Actually, Takua does have a “I don’t care what order the tiles are in” mode, which does in fact just run a tbb::parallel_for over all of the tiles and lets tbb’s underlying scheduler decide what order the tiles are dispatched in; rendering tiles in a specific order doesn’t actually matter for correctness.
However, maintaining a specific tile ordering does make user feedback a bit nicer.
Implementing a work dispatcher that can still maintain a specific tile ordering requires some mechanism internally to track what the next tile that should be dispatched is; Takua does so using an atomic integer inside of the work dispatcher.
This atomic is where the memory-reordering bug comes in that led to Takua occasionally dropping a single spp for a single tile on arm64.
Here’s some pesudo-code for how threads are launched and how they ask the work dispatcher for tiles to render; this is highly simplified and condensed from how the actual code in Takua is written (specifically, I’ve inlined together code from both individual threads and from the work dispatcher and removed a bunch of other unrelated stuff), but preserves all of the important details necessary to illustrate the bug:
int nextTileIndex = 0;
std::atomic<bool> nextTileSoftLock(false);
tbb::parallel_for(int(0), numberOfTilesToRender, [&](int /*i*/) {
bool gotNewTile = false;
int tile = -1;
while (!gotNewTile) {
bool expected = false;
if (nextTileSoftLock.compare_exchange_strong(expected, true, std::memory_order_relaxed)) {
tile = nextTileIndex++;
nextTileSoftLock.store(false, std::memory_order_relaxed);
gotNewTile = true;
}
}
if (tileIsInRange(tile)) {
renderTile(tile);
}
});
Listing 1: Simplified pseudocode for the not-very-good work scheduling mechanism Takua used to assign tiles to threads. This version of the scheduler resulted in tiles occasionally being missed on arm64, but not on x64-64.
If you remember your memory ordering rules, you already know what’s wrong with the code above; this code is really really bad!
In my defense, this code is an ancient part of Takua’s codebase; I wrote it back in college and haven’t really revisited it since, and back when I wrote it, I didn’t have the strongest grasp of memory ordering rules and how they apply to concurrent programming yet.
First off, why does this code use an atomic bool as a makeshift mutex so that multiple threads can increment a non-atomic integer, as opposed to just using an atomic integer?
Looking through the commit history, the earliest version of this code that I first prototyped (some eight years ago!) actually relied on a full-blown std::mutex to protect from race conditions around incrementing nextTileIndex; I must have prototyped this code completely single-threaded originally and then done a quick-and-dirty multithreading adaptation by just wrapping a mutex around everything, and then replaced the mutex with a cheaper atomic bool as an incredibly lazy port to a lock-free implementation instead of properly rewriting things.
I haven’t had to modify it since then because it worked well enough, so over time I must have just completely forgotten about how awful this code is.
Anyhow, the fix for the code above is simple enough: just replace the first std::memory_order_relaxed in line 8 with std::memory_order_acquire and replace the second std::memory_order_relaxed in line 10 with std::memory_order_release.
An even better fix though is to just outright replace the combination of an atomic bool and non-atomic integer incremented with a single atomic integer incrementer, which is what I actually did.
But, going back to the original code, why exactly does using std::memory_order_relaxed produce correctly functioning code on x86-64, but produces code that occasionally drops tiles on arm64?
Well, first, why did I use std::memory_order_relaxed in the first place?
My commit comments from eight years ago indicate that I chose std::memory_order_relaxed because I thought it would compile down to something cheaper than if I had chosen some other memory ordering flag; I really didn’t understand this stuff back then!
I wasn’t entirely wrong, although not for the reasons that I thought at the time.
On x86-64, different memory order flags don’t actually do anything, since x86-64 has a guaranteed strong memory model.
On arm64, using std::memory_order_relaxed instead of std::memory_order_acquire/std::memory_order_release does indeed produce simpler and faster arm64 assembly, but the simpler and faster arm64 assembly is also wrong for what the code is supposed to do.
Understanding why the above happens on arm64 but not on x86-64 requires understanding what a weakly ordered CPU is versus what a strong ordered CPU is; arm64 is a weakly ordered architecture, whereas x86-64 is a strongly ordered architecture.
One of the best resources on diving deep into weak versus strong memory orderings is the well-known series of articles by Jeff Preshing on the topic (parts 1, 2, 3, 4, 5, 6, and 7).
Actually, while I was going back through the Preshing on Programming series in preparation to write this post, I noticed that by hilarious coincidence the older code in Takua represented by Listing 1, once boiled down to what it is fundamentally doing, is extremely similar to the canonical example used in Preshing on Programming’s “This Is Why They Call It a Weakly-Ordered CPU” article.
If only I had read the Preshing on Programming series a year before implementing Takua’s work assignment system instead of a few years after!
I’ll do my best to quickly recap what the Preshing on Programming series covers about weak versus strong memory orderings here, but if you have not read Jeff Preshing’s articles before, I’d recommend taking some time later to do so.
One of the single most important things that lock-free multithreaded code needs to take into account is the potential for memory reordering.
Memory reordering is when the compiler and/or the processor decides to optimize code by changing the ordering of instructions that access and modify memory.
Memory reordering is always carried out in such a way that the behavior of a single-threaded program never changes, and multithreaded code using locks such as mutexes forces the compiler and processor to not reorder instructions across the boundaries defined by locks.
However, lock-free multithreaded code is basically free range for the compiler and processor to do whatever they want; even though memory reordering is carried out for each individual thread in such a way that keeps the apparent behavior of that specific thread the same as before, this rule does not take into account the interactions between threads, so different reorderings in different threads that keep behavior the same in each thread isolated can still result in very different behavior in the overall multithreaded behavior.
The easiest way to disable any kind of memory reordering at compile time is to just… disable all compiler optimizations.
However, in practice we never actually want to do this, because disabling compiler optimizations means all of our code will run slower (sometimes a lot slower).
Instruction selection to lower from IR to assembly also means that even disabling all compiler optimizations may not be enough to ensure no memory reordering, because we still need to contend with potential memory reordering at runtime from the CPU.
Memory reordering in multithreaded code happens on the CPU because of how CPUs access memory: modern processors have a series of caches (L1, L2, sometimes L3, etc) sitting between the actual registers in each CPU core and main memory.
Some of these cache levels (usually L1) are per-CPU-core, and some of these cache levels (usually L2 and higher) are shared across some or all cores.
The lower the cache level number, the faster and also smaller that cache level typically is, and the higher the cache level number, the slower and larger that cache level is.
When a CPU wants to read a particular piece of data, it will check for it in cache first, and if the value is not in cache, then the CPU must make a fetch request to main memory for the value; fetching from main memory is obviously much slower than fetching from cache.
Where these caches get tricky is how data is propagated from a given CPU core’s registers and caches back to main memory and then eventually up again into the L1 caches for other CPU cores.
This propagation can happen… whenever!
A variety of different possible implementation strategies exist for when caches update from and write back to main memory, with the end result being that by default we as programmers have no reliable way of guessing when data transfers between cache and main memory will happen.
Imagine that we have some multithreaded code written such that one thread writes, or stores, to a value, and then a little while later, another thread reads, or loads, that same value.
We would expect the store on the first thread to always precede the load on the second thread, so the second thread should always pick up whatever value the first thread read.
However, if we implement this code just using a normal int or float or bool or whatever, what can actually happen at runtime is our first thread writes the value to L1 cache, and then eventually the value in L1 cache gets written back to main memory.
However, before the value manages to get propagated from L1 cache back to main memory, the second thread reads the value out of main memory.
In this case, from the perspective of main memory, the second thread’s load out of main memory takes place before the first thread’s store has rippled back down to main memory.
This case is an example of StoreLoad reordering, so named because a store has been reordered with a later load.
There are also LoadStore, LoadLoad, and StoreStore reorderings that are possible.
Jeff Preshing’s “Memory Barriers are Like Source Control” article does a great job of describing these four possible reordering scenarios in detail.
Different CPU architectures make different guarantees about which types of memory reordering can and can’t happen on that particular architecture at the hardware level.
A processor that guarantees absolutely no memory reordering of any kind is said to have a sequentially consistent memory model.
Few, if any modern processor architecture provide a guaranteed sequentially consistent memory model.
Some processors don’t guarantee absolutely sequential consistency, but do guarantee that at least when a CPU core makes a series of writes, other CPU cores will see those writes in the same sequence that they were made; CPUs that make this guarantee have a strong memory model.
Strong memory models effectively guarantee that StoreLoad reordering is the only type of reordering allowed; x86-64 has a strong memory model.
Finally, CPUs that allow for any type of memory reordering at all are said to have a weak memory model.
The arm64 architecture uses a weak memory model, although arm64 at least guarantees that if we read a value through a pointer, the value read will be at least as new as the pointer itself.
So, how can we possibly hope to be able to reason about multithreaded code when both the compiler and the processor can happily reorder our memory access instructions between threads whenever they want for whatever reason they want?
The answer is in memory barriers and fence instructions; these tools allow us to specify boundaries that the compiler cannot reorder memory access instructions across and allow us to force the CPU to make sure that values are flushed to main memory before being read.
In C++, specifying barriers and fences can be done by using compiler intrinsics that map to specific underlying assembly instructions, but the easier and more common way of doing this is by using std::memory_order flags in combination with atomics.
Other languages have similar concepts; for example, Rust’s atomic access flags are very similar to the C++ memory ordering flags.
std::memory_order flags specify how memory accesses for all operations surrounding an atomic are to be ordered; the impacted surrounding operations include all non-atomics.
There are a whole bunch of std::memory_order flags; we’ll examine the few that are relevant to the specific example in Listing 1.
The heaviest hammer of all of the flags is std::memory_order_seq_cst, which enforces absolute sequential consistency at the cost of potentially being more expensive due to potentially needing more loads and/or stores.
For example, on x86-64, std::memory_order_seq_cst is often implemented using slower xchg or paired mov/mfence instructions instead of a single mov instruction, and on arm64, the overhead is even greater due to arm64’s weak memory model.
Using std::memory_order_seq_cst also potentially disallows the CPU from reordering unrelated, longer running instructions to starting (and therefore finish) earlier, potentially causing even more slowdowns.
In C++, atomic operations default to using std::memory_order_seq_cst if no memory ordering flag is explicitly specified.
Contrast with std::memory_order_relaxed, which is the exact opposite of std::memory_order_seq_cst.
std::memory_order_relaxed enforces no synchronization or ordering constraints whatsoever; on an architecture like x86-64, using std::memory_order_relaxed can be faster than using std::memory_order_seq_cst if your memory ordering requirements are already met in hardware by x86-64’s strong memory model.
However, being sloppy with std::memory_order_relaxed can result in some nasty nondeterministic bugs on arm64 if your code requires specific memory ordering guarantees, due to arm64’s weak memory model.
The above is the exact reason why the code in Listing 1 occasionally resulted in dropped tiles in Takua on arm64!
Without any kind of memory ordering constraints, with arm64’s weak memory ordering, the code in Listing 1 can sometimes execute in such a way that one thread sets nextTileSoftLock to true, but another thread attempts to check nextTileSoftLock before the first thread’s new value propagates back to main memory and to all of the other threads.
As a result, two threads can end up in a race condition, trying to both increment the non-atomic nextTileIndex at the same time.
When this happens, two threads can end up working on the same tile at the same time or a tile can get skipped!
We could fix this problem by just removing the memory ordering flags entirely from Listing 1, allowing everything to default back to std::memory_order_seq_cst, which would fix the problem.
However, as just mentioned above, we can do better than using std::memory_order_seq_cst if we know specifically what memory ordering requirements we need for the code to work correctly.
Enter std::memory_order_acquire and std::memory_order_release, which represent acquire semantics and release semantics respectively and, when used correctly, always come in a pair.
Acquire semantics apply to load (read) operations and prevent memory ordering of the load operation
with any subsequent read or write operation.
Release semantics apply to store (write) operations and prevent memory reordering of the store operation with any preceding read or write operation.
In other words, std::memory_order_acquire tells the compiler to issue instructions that prevent LoadLoad and LoadStore reordering from happening, and std::memory_order_release tells the compiler to issue instructions that prevent LoadStore and StoreStore reordering from happening.
Using acquire and release semantics allows Listing 1 to work correctly on arm64, while being ever so slightly cheaper compared with enforcing absolute sequential consistency everywhere.
What is the takeaway from this long tour through memory reordering and weak and strong memory models and memory ordering constraints?
The takeaway is that when writing multithreaded code that needs to be portable across architectures with different memory ordering guarantees, such as x86-64 versus arm64, we need to be very careful with thinking about how each architecture’s memory ordering guarantees (or lack thereof) impact any lock-free cross-thread communication we need to do!
Atomic code often can be written more sloppily on x86-64 than on arm64 and still have a good chance of working, whereas arm64’s weak memory model means there’s much less room for being sloppy.
If you want a good way to smoke out potential bugs in your lock-free atomic code, porting to arm64 is a good way to find out!
A Deep Dive on x86-64 versus arm64 Through the Lens of Compiling std::atomic::compare_exchange_weak()
While I was looking for the source of the memory reordering bug, I found a separate interesting bug in Takua’s atomic framebuffer… or at least, I thought it was a bug.
The thing I found turned out to not be a bug at all in the end, but at the time I thought that there was a bug in the form of a race condition in an atomic compare-and-exchange loop.
I figured that the renderer must be just running correctly most of the time instead of all of the time, but as I’ll explain in a little bit, the renderer actually provably runs correctly 100% of the time.
Understanding what was going on here led me to dive into the compiler’s assembly output, and wound up being an interesting case study in comparing how the same exact C++ source code compiles to x86-64 versus arm64.
In order to provide the context for the not-a-bug and what I learned about arm64 from it, I need to first briefly describe what Takua’s atomic framebuffer is and how it is used.
Takua supports multiple threads writing to the same pixel in the framebuffer at the same time.
There are two major uses cases for this capability: first, integration techniques that use light tracing will connect back to the camera completely arbitrarily, resulting in splats to the framebuffer that are completely unpredictable and possibly overlapping on the same pixels.
Second, adaptive sampling techniques that redistribute sample allocation within a single iteration (meaning launching a single set of pixel samples) can result in multiple samples for the same pixel in the same iteration, which means multiple threads can be calculating paths starting from the same pixel and therefore multiple threads need to write to the same framebuffer pixel.
In order to support multiple threads writing simultaneously to the same pixel in the framebuffer, there are three possible implementation options.
The first option is to just keep a separate framebuffer per thread and merge afterwards, but this approach obviously requires potentially a huge amount of memory.
The second option is to never write to the framebuffer directly, but instead keep queues of framebuffer write requests that occasionally get flushed to the framebuffer by a dedicated worker thread (or some variation thereof).
The third option is to just make each pixel in the framebuffer support exclusive operations through atomics (a mutex per pixel works too, but obviously this would involve much more overhead and might be slower); this option is the atomic framebuffer.
I actually implemented the second option in Takua a long time ago, but the added complexity and performance impact of needing to flush the queue led me to eventually replace the whole thing with an atomic framebuffer.
The tricky part of implementing an atomic framebuffer in C++ is the need for atomic floats.
Obviously each pixel in the framebuffer has to store at the very least accumulated radiance values for the base RGB primaries, along with potentially other AOV values, and accumulated radiance values and many common AOVs all have to be represented with floats.
Modern C++ has standard library support for atomic types through std::atomic, and std::atomic works with floats.
However, pre-C++20, std::atomic only provides atomic arithmetic operations for integer types.
C++20 adds fetch_add() and fetch_sub() implementations for std::atomic<float>, but I wrote Takua’s atomic framebuffer way back when C++11 was still the latest standard.
So, pre-C++20, if you want atomic arithmetic operations for std::atomic<float>, you have to implement it yourself.
Fortunately, pre-C++20 does provide compare_and_exchange() implementations for all atomic types, and that’s all we need to implement everything else we need ourselves.
Implementing fetch_add() for atomic floats is fairly straightforward.
Let’s say we want to add a value f1 to an atomic float f0.
The basic idea is to do an atomic load from f0 into some temporary variable oldval.
A standard compare_and_exchange() implementation compares some input value with the current value of the atomic float, and if the two are equal, replaces the current value of the atomic float with a second input value; C++ provides an implementations in the form of compare_exchange_weak() and compare_exchange_strong().
So, all we need to do is run compare_exchange_weak() on f0 where the value we use for the comparison test is oldval and the replacement value is oldval + f1; if compare_exchange_weak() succeeds, we return oldval, otherwise, loop and repeat until compare_exchange_weak() succeeds.
Here’s an example implementation:
float addAtomicFloat(std::atomic<float>& f0, const float f1) {
do {
float oldval = f0.load();
float newval = oldval + f1;
if (f0.compare_exchange_weak(oldval, newval)) {
return oldval;
}
} while (true);
}
Listing 2: Example implementation of atomic float addition.
Seeing why the above implementation works should be very straightforward: imagine two threads are calling the above implementation at the same time.
We want each thread to reload the atomic float on each iteration because we never want a situation where a first thread loads from f0, a second thread succeeds in adding to f0, and then the first thread also succeeds in writing its value to f0, because upon the first thread writing, the value of f0 that the first thread used for the addition operation is out of date!
Well, here’s the implementation that has actually been in Takua’s atomic framebuffer implementation for most of the past decade.
This implementation is very similar to Listing 2, but compared with Listing 2, Lines 2 and 3 are swapped from where they should be; I likely swapped these two lines through a simple copy/paste error or something when I originally wrote it.
This is the implementation that I suspected was a bug upon revisiting it during the arm64 porting process:
float addAtomicFloat(std::atomic<float>& f0, const float f1) {
float oldval = f0.load();
do {
float newval = oldval + f1;
if (f0.compare_exchange_weak(oldval, newval)) {
return oldval;
}
} while (true);
}
Listing 3: What I thought was an incorrect implementation of atomic float addition.
In the Listing 3 implementation, note how the atomic load of f0 only ever happens once outside of the loop.
The following is what I thought was going on and why at the moment I thought this implementation was wrong:
Think about what happens if a first thread loads from f0 and then a second thread’s call to compare_exchange_weak() succeeds before the first thread gets to compare_exchange_weak(); in this race condition scenario, the first thread should get stuck in an infinite loop.
Since the value of f0 has now been updated by the second thread, but the first thread never reloads the value of f0 inside of the loop, the first thread should have no way of ever succeeding at thecompare_exchange_weak()call!
However, in reality, with the Listing 3 implementation, Takua never actually gets stuck in an infinite loop, even when multiple threads are writing to the same pixel in the atomic framebuffer.
I initially thought that I must have just been getting really lucky every time and multiple threads, while attempting to accumulate to the same pixel, just never happened to produce the specific compare_exchange_weak() call ordering that would cause the race condition and infinite loop.
But then I repeatedly tried a simple test where I had 32 threads simultaneously call addAtomicFloat() for the same atomic float a million times per thread, and… still an infinite loop never occurred.
So, the situation appeared to be that what I thought was incorrect code was always behaving as if it had been written correctly, and furthermore, this held true on both x86-64 and on arm64, across both compiling with Clang on macOS and compiling with GCC on Linux.
If you are well-versed in the C++ specifications, you already know which crucial detail I had forgotten that explains why Listing 3 is actually completely correct and functionally equivalent to Listing 2.
Under the hood, std::atomic<T>::compare_exchange_weak(T& expected, T desired) requires doing an atomic load of the target value in order to compare the target value with expected.
What I had forgotten was that if the comparison fails, std::atomic<T>::compare_exchange_weak() doesn’t just return a false bool; the function also replacesexpected with the result of the atomic load on the target value!
So really, there isn’t only a single atomic load of f0 in Listing 3; there’s actually an atomic load of f0 in every loop as part of compare_exchange_weak(), and in the event that the comparison fails, the equivalent of oldval = f0.load() happens.
Of course, I didn’t actually correctly remember what compare_exchange_weak() does in the comparison failure case, and I stupidly didn’t double check cppreference, so it took me much longer to figure out what was going on.
So, still missing the key piece of knowledge that I had forgotten and assuming that compare_exchange_weak() didn’t modify any inputs upon comparison failure, my initial guess was that perhaps the compiler was inlining f0.load() wherever oldval was being used as an optimization, which would produce a result that should prevent the race condition from ever happening.
However, after a bit more thought, I concluded that this optimization was very unlikely, since it both changes the written semantics of what the code should be doing by effectively moving an operation from outside a loop to the inside of the loop, and also inlining f0.load() wherever oldval is used is not actually a safe code transformation and can produce a different result from the originally written code, since having two atomic loads from f0 introduces the possibility that another thread can do an atomic write to f0 in between the current thread’s two atomic loads.
Things got even more interesting when I tried adding in an additional bit of indirection around the atomic load of f0 into oldval.
Here is an actually incorrect implementation that I thought should be functionally equivalent to the implementation in Listing 3:
Listing 4: An actually incorrect implementation of atomic float addition that might appear to be semantically identical to the implementation in Listing 3 if you've forgotten a certain very important detail about std::compare_exchange_weak().
Creating the race condition and subsequent infinite loop is extremely easy and reliable with Listing 4.
So, to summarize where I was at this point: Listing 2 is a correctly written implementation that produces a correct result in reality, Listing 4 is an incorrectly written implementation that, as expected, produces an incorrect result in reality, and Listing 3 is what I thought was an incorrectly written implementation that I thought was semantically identical to Listing 4, but actually produces the same correct result in reality as Listing 2!
So, left with no better ideas, I decided to just go look directly at the compiler’s output assembly.
To make things a bit easier, we’ll look at and compare the x86-64 assembly for the Listing 2 and Listing 3 C++ implementations first, and explain what important detail I had missed that led me down this wild goose chase.
Then, we’ll look at and compare the arm64 assembly, and we’ll discuss some interesting things I learned along the way by comparing the x86-64 and arm64 assembly for the same C++ function.
Here is the corresponding x86-64 assembly for the correct C++ implementation in Listing 2, compiled with Clang 10.0.0 using -O3.
For readers who are not very used to reading assembly, I’ve included annotations as comments in the assembly code to describe what the assembly code is doing and how it corresponds back to the original C++ code:
Listing 5: x86-64 assembly corresponding to the implementation in Listing 2, with my annotations in the comments. Compiled using armv8-a Clang 10.0.0 using -O3. See on Godbolt Compiler Explorer
Here is the corresponding x86-64 assembly for the C++ implementation in Listing 3; again, this is the version that produces the same correct result as Listing 2.
Just like with Listing 5, this was compiled using Clang 10.0.0 using -O3, and descriptive annotations are in the comments:
Listing 6: x86-64 assembly corresponding to the implementation in Listing 3, with my annotations in the comments. Compiled using armv8-a Clang 10.0.0 using -O3. See on Godbolt Compiler Explorer
The compiled x86-64 assembly in Listing 5 and Listing 6 is almost identical; the only difference is that in Listing 5, copying data from the address stored in register rdi to register eax happens after label .LBB0_1 and in Listing 6 the copy happens before label .LBB0_1.
Comparing the x86-64 assembly with the C++ code, we can see that this difference corresponds directly to where f0’s value is atomically loaded into oldval.
We can also see that std::atomic<float>::compare_exchange_weak() compiles down to a single cmpxchg instruction, which as the instruction name suggests, is a compare and exchange operation.
The lock instruction prefix in front of cmpxchg ensures that the current CPU core has exclusive ownership of the corresponding cache line for the duration of the cmpxchg operation, which is how the operation is made atomic.
This is the point where I eventually realized what I had missed.
I actually didn’t notice immediately; figuring out what I had missed didn’t actually occur to me until several days later!
The thing that finally made me realize what I had missed and made me understand why Listing 3 / Listing 6 don’t actually result in an infinite loop and instead match the behavior of Listing 2 / Listing 5 lies in cmpxchg.
Let’s take a look at the official Intel 64 and IA-32 Architectures Software Developer’s Manual’s description [Intel 2021] of what cmpxchg does:
Compares the value in the AL, AX, EAX, or RAX register with the first operand (destination operand). If the two values are equal, the second operand (source operand) is loaded into the destination operand. Otherwise, the destination operand is loaded into the AL, AX, EAX or RAX register. RAX register is available only in 64-bit mode.
This instruction can be used with a LOCK prefix to allow the instruction to be executed atomically. To simplify the interface to the processor’s bus, the destination operand receives a write cycle without regard to the result of the comparison. The destination operand is written back if the comparison fails; otherwise, the source operand is written into the destination. (The processor never produces a locked read without also producing a locked write.)
If the compare part of cmpxchg fails, the first operand is loaded into the EAX register!
After thinking about this property of cmpxchg for a bit, I finally had my head-smack moment and remembered that std::atomic<T>::compare_exchange_weak(T& expected, T desired) replaces expected with the result of the atomic load in the event of comparison failure.
This property of std::atomic<T>::compare_exchange_weak() is why std::atomic<T>::compare_exchange_weak() can be compiled down to a single cmpxchg instruction on x86-64 in the first place.
We can actually see the compiler being clever here in Listing 6 and exploiting the fact that cmpxchg comparison failure mode writes into the eax register: the compiler chooses to use eax as the target for the mov instruction in Line 1 instead of using some other register so that a second move from eax into some other register isn’t necessary after cmpxchg.
If anything, the implementation in Listing 3 / Listing 6 is actually slightly more efficient than the implementation in Listing 2 / Listing 5, since there is one fewer mov instruction needed in the loop.
So what does this have to do with learning about arm64?
Well, while I was in the process of looking at the x86-64 assembly to try to understand what was going on, I also tried the implementation in Listing 3 on my Raspberry Pi 4B just to sanity check if things worked the same on arm64.
At that point I hadn’t realized that the code in Listing 3 was actually correct yet, so I was beginning to consider possibilities like a compiler bug or weird platform-specific considerations that I hadn’t thought of, so to rule those more exotic explanations out, I decided to see if the code worked the same on x86-64 and arm64.
Of course the code worked exactly the same on both, so the next step was to also examine the arm64 assembly in addition to the x86-64 assembly.
Comparing the same code’s corresponding assembly for x86-64 and arm64 at the same time proved to be a very interesting exercise in getting to better understand some low-level and general differences between the two instruction sets.
Here is the corresponding arm64 assembly for the implementation in Listing 2; this is the arm64 assembly that is the direct counterpart to the x86-64 assembly in Listing 5.
This arm64 assembly was also compiled with Clang 10.0.0 using -O3.
I’ve included annotations here as well, although admittedly my arm64 assembly comprehension is not as good as my x86-64 assembly comprehension, since I’m relatively new to compiling for arm64.
If you’re well versed in arm64 assembly and see a mistake in my annotations, feel free to send me a correction!
addAtomicFloat(std::atomic<float>&, float):
b .LBB0_2 // goto .LBB0_2
.LBB0_1:
clrex // clear this thread's record of exclusive lock
.LBB0_2:
ldar w8, [x0] // w8 = *arg0 = f0, non-atomically loaded
ldaxr w9, [x0] // w9 = *arg0 = f0.load(), atomically
// loaded (get exclusive lock on x0), with
// implicit synchronization
fmov s1, w8 // s1 = w8 = f0
fadd s2, s1, s0 // s2 = s1 + s0 = (f0 + f1)
cmp w9, w8 // compare non-atomically loaded f0 with atomically
// loaded f0 and store result in N
b.ne .LBB0_1 // if N==0 { goto .LBB0_1 }
fmov w8, s2 // w8 = s2 = (f0 + f1)
stlxr w9, w8, [x0] // if this thread has the exclusive lock,
// { *arg0 = w8 = (f0 + f1), release lock },
// store whether or not succeeded in w9
cbnz w9, .LBB0_2 // if w9 says exclusive lock failed { goto .LBB0_2}
mov v0.16b, v1.16b // return f0 value from ldaxr
ret
Listing 7: arm64 assembly corresponding to Listing 2, with my annotations in the comments. Compiled using arm64 Clang 10.0.0 using -O3. See on Godbolt Compiler Explorer
I should note here that the specific version of arm64 that Listing 7 was compiled for is ARMv8.0-A, which is what Clang and GCC both default to when compiling for arm64; this detail will become important a little bit later in this post.
When we compare Listing 7 with Listing 5, we can immediately see some major differences between the arm64 and x86-64 instruction sets, aside from superficial stuff like how registers are named.
The arm64 version is just under twice as long as the x86-64 version, and examining the code, we can see that most of the additional length comes from how the atomic compare-and-exchange is implemented.
Actually, the rest of the code is very similar; the rest of the code is just moving stuff around to support the addition operation and to deal with setting up and jumping to the top of the loop.
In the compare and exchange code, we can see that the arm64 version does not have a single instruction to implement the atomic compare-and-exchange!
While the x86-64 version can compile std::atomic<float>::compare_exchange_weak() down into a single cmpxchg instruction, ARMv8.0-A has no equivalent instruction, so the arm64 version instead must use three separate instructions to implement the complete functionality: ldaxr to do an exclusive load, stlxr to do an exclusive store, and clrex to reset the current thread’s record of exclusive access requests.
This difference speaks directly towards x86-84 being a CISC architecture and arm64 being a RISC architecture.
x86-64’s CISC nature calls for the ISA to have a large number of instructions carrying out complex often-multistep operations, and this design philosophy is what allows x86-64 to encode complex multi-step operations like a compare-and-exchange as a single instruction.
Conversely, arm64’s RISC nature means a design consisting of fewer, simpler operations [Patterson and Ditzel 1980]; for example, the RISC design philosophy mandates that memory access be done through specific single-cycle instructions instead of as part of a more complex instruction such as compare-and-exchange.
These differing design philosophies mean that in arm64 assembly, we will often see many instructions used to implement what would be a single instruction in x86_64; given this difference, compiling Listing 2 produces surprisingly structurally similarities in the output x86_64 (Listing 5) and arm64 (Listing 7) assembly.
However, if we take the implementation of addAtomicFloat() in Listing 3 and compile it for arm64’s ARMv8.0-A revision, structural differences between the x86-64 and arm64 output become far more apparent:
addAtomicFloat(std::atomic<float>&, float):
ldar w9, [x0] // w9 = *arg0 = f0, non-atomically loaded
ldaxr w8, [x0] // w8 = *arg0 = f0.load(), atomically
// loaded (get exclusive lock on x0), with
// implicit synchronization
fmov s1, w9 // s1 = s9 = f0
cmp w8, w9 // compare non-atomically loaded f0 with atomically
// loaded f0 and store result in N
b.ne .LBB0_3 // if N==0 { goto .LBB0_3 }
fadd s2, s1, s0 // s2 = s1 + s0 = (f0 + f1)
fmov w9, s2 // w9 = s2 = (f0 + f1)
stlxr w10, w9, [x0] // if this thread has the exclusive lock,
// { *arg0 = w9 = (f0 + f1), release lock },
// store whether or not succeeded in w10
cbnz w10, .LBB0_4. // if w10 says exclusive lock failed { goto .LBBO_4 }
mov w9, #1. // w9 = 1 (???)
tbz w9, #0, .LBB0_8. // if bit 0 of w9 == 0 { goto .LBB0_8 }
b .LBB0_5 // goto .LBB0_5
.LBB0_3:
clrex. // clear this thread's record of exclusive lock
.LBB0_4:
mov w9, wzr // w9 = 0
tbz w9, #0, .LBB0_8 // if bit 0 of w9 == 0 { goto .LBBO_8 }
.LBB0_5:
mov v0.16b, v1.16b. // return f0 value from ldaxr
ret
.LBB0_6:
clrex // clear this thread's record of exclusive lock
.LBB0_7:
mov w10, wzr // w10 = 0
mov w8, w9 // w8 = w9
cbnz w10, .LBB0_5 // if w10 is not zero { goto .LBB0_5 }
.LBB0_8:
ldaxr w9, [x0] // w9 = *arg0 = f0.load(), atomically
// loaded (get exclusive lock on x0), with
// implicit synchronization
fmov s1, w8 // s1 = w0 = f0
cmp w9, w8 // compare non-atomically loaded f0 with atomically
// loaded f0 and store result in N
b.ne .LBB0_6 // if N==0 { goto .LBBO_6 }
fadd s2, s1, s0 // s2 = s1 + s0 = (f0 + f1)
fmov w8, s2 // w2 = s2 = (f0 + f1)
stlxr w10, w8, [x0] // if this thread has the exclusive lock,
// { *arg0 = w8 = (f0 + f1), release lock },
// store whether or not succeeded in w10
cbnz w10, .LBB0_7 // if w10 says exclusive lock failed { goto .LBB0_7 }
mov w10, #1 // w10 = 1
mov w8, w9 // w8 = w9 = f0.load()
cbz w10, .LBB0_8 // if w10==0 { goto .LBB0_8 }
b .LBB0_5 // goto .LBB0_5
Listing 8: arm64 assembly corresponding to Listing 3, with my annotations in the comments. Compiled using arm64 Clang 10.0.0 using -O3. See on Godbolt Compiler Explorer
Moving the atomic load out of the loop in Listing 3 resulted in a single line change between Listing 5 and Listing 6’s x86-64 assembly, but causes the arm64 version to explode in size and radically change in structure between Listing 7 and Listing 8!
The key difference between Listing 7 and Listing 8 is that in Listing 8, the entire first iteration of the while loop is lifted out into it’s own code segment, which can then either directly return out of the function or go into the main body of the loop afterwards.
I initially thought that Clang’s decision to lift out the first iteration of the loop was surprising, but it turns out that GCC 10.3 and MSVC v19.28’s respective arm64 backends also similarly decide to lift the first iteration of the loop out as well.
The need to lift the entire first iteration out of the loop likely comes from the need to use an ldaxr instruction to carry out the initial atomic load of f0.
Compared with GCC 10.3 and MSVC v19.28 though, Clang 10.0.0’s arm64 output does seem to do a bit more jumping around (see .LBB0_4 through .LBBO_7) though.
Also, admittedly I’m not entirely sure why register w9 gets set to 1 and then immediately compared with 0 in lines 16/17 and lines 47/49; maybe that’s just a convenient way to clear the z bit of the CPSR (Current Program Status Register; this is analogous to EFLAG on x86-64)?
But anyhow, compared with Listing 7, the arm64 assembly in Listing 8 is much longer in terms of code length, but actually is only slightly more inefficient in terms of total instructions executed.
The slight additional inefficiency comes from some of the additional setup work needed to manage all of the jumping and the split loop.
However, the fact that Listing 8 is less efficient compared with Listing 7 is interesting when we compare with what Listing 3 does to the x86-64 assembly; in the case of x86-64, pulling the initial atomic load out of the loop makes the output x86-64 assembly slightly more efficient, as opposed to slightly less efficient as we have here with arm64.
As a very loose general rule of thumb, arm64 assembly tends to be longer than the equivalent x86-64 assembly for the same high-level code because CISC architectures simply tend to encode a lot more stuff per instruction compared with RISC architectures [Weaver and McKee 2009].
However, compiled x86-64 binaries having fewer instructions doesn’t actually mean x86-64 binaries necessarily runs faster than equivalent, less “instruction-dense” compiled arm64 binary.
x86-64 instructions are variable length, requiring more complex logic in the processor’s instruction decoder, and also since x86-64 instructions are more complex, they can take many more cycles per instruction to execute.
Contrast with arm64, in which instructions are fixed length.
Generally RISC architectures usually feature fixed length instructions, although this generalization isn’t a hard rule; the SuperH architecture (famously used in the Sega Saturn and Sega Dreamcast) is notably a RISC architecture with variable length instructions.
Fixed length instructions allow for arm64 chips to have simpler logic in decoding, and arm64 also tends to take many many fewer instructions per cycle (often, but not always, as low as one or two cycles per instruction).
The end result is that even though compiled arm64 binaries have lower instruction-density than compiled x86-64 binaries, arm64 processors tend to be able to retire more instructions per cycle than comparable x86-64 processors, allowing arm64 as an architecture to make up for the difference in code density.
…except, of course, all of the above is only loosely true today!
While the x86-64 instruction set is still definitively a CISC instruction set today and the arm64 instruction set is still clearly a RISC instruction set today, a lot of the details have gotten fuzzier over time.
Processors today rarely directly implement the instruction set that they run; basically all modern x86-64 processors today feed x86-64 instructions into a huge hardware decoder block that breaks down individual x86-64 instructions into lower-level micro-operations, or μops.
Compared with older x86 processors from decades ago that directly implemented x86, these modern micro-operation-based x86-64 implementations are often much more RISC-like internally.
In fact, if you were to examine all of the parts of a modern Intel and AMD x86-64 processor that take place after the instruction decoding phase, without knowing what processor you were looking at beforehand, you likely would not be able to determine if the processor implemented a CISC or a RISC ISA [Thomadakis 2011].
The same is true going the other way; while modern x86-64 is a CISC architecture that in practical implementation is often more RISC-like, modern arm64 is a RISC architecture that sometimes has surprisingly CISC-like elements if you look closely.
Modern arm64 processors often also decode individual instructions into smaller micro-operations [ARM 2016], although the extent to which modern arm64 processors do this is a lot less intensive than what modern x86-64 does [Castellano 2015].
Modern arm64 instruction decoders usually rely on simple hardwired control to break instructions down into micro-operations, whereas modern x86-64 must use a programmable ROM containing advanced microcode to store mappings from x86-64 instructions to micro-instructions.
Another way that arm64 has slowly gained some CISC-like characteristics is that arm64 over time has gained some surprisingly specialized complex instructions!
Remember the important note I made earlier about Listing 7 and Listing 8 being generated specifically for the ARMv8.0-A revision of arm64?
Well, the specific ldaxr/stlxr combination in Listings 6 and 7 that is needed to implement an atomic compare-and-exchange (and generally any kind of atomic load-and-conditional-store operation) is a specific area where a more complex single-instruction implementation generally can perform better than an implementation using several instructions.
As discussed earlier, one complex instruction is not necessarily always faster than several simpler instructions due to how the instructions actually have to be decoded and executed, but in this case, one atomic instruction allows for a faster implementation than several instructions combined since a single atomic instruction can take advantage of more available information at once [Cownie 2021].
Accordingly, the ARMv8.1-A revision of arm64 introduces a collection of new single-instruction atomic operations.
Of interest to our particular example here is the new casal instruction, which performs a compare-and-exchange to memory with acquire and release semantics; this new instruction is a direct analog to the x86_64 cmpxchg instruction with the lock prefix.
We can actually use these new ARMv8.1-A single-instruction atomic operations today; while GCC and Clang both target ARMv8.0-A by default today, ARMv8.1-A support can be enabled using the -march=armv8.1-a flag starting in GCC 10.1 and starting in Clang 9.0.0.
Actually, Clang’s support might go back even earlier; Clang 9.0.0 was the furthest back I was able to test.
Here’s what Listing 2 compiles to using the -march=armv8.1-a flag to enable the casal instruction:
addAtomicFloat(std::atomic<float>&, float):
.LBB0_1:
ldar w8, [x0] // w8 = *arg0 = f0, non-atomically loaded
fmov s1, w8 // s1 = w8 = f0
fadd s2, s1, s0 // s2 = s1 + s0 = (f0 + f1)
mov w9, w8 // w9 = w8 = f0
fmov w10, s2 // w10 = s2 = (f0 + f1)
casal w9, w10, [x0] // atomically read the contents of the address stored
// in x0 (*arg0 = f0) and compare with w9;
// if [x0] == w9:
// atomically set the contents of the
// [x0] to the value in w10
// else:
// w9 = value loaded from [x0]
cmp w9, w8 // compare w9 and w8 and store result in N
cset w8, eq // if previous instruction's compare was true,
// set w8 = 1
cmp w8, #1 // compare if w8 == 1 and store result in N
b.ne .LBB0_1 // if N==0 { goto .LBB0_1 }
mov v0.16b, v1.16b // return f0 value from ldar
ret
Listing 9: arm64 revision ARMv8.1-A assembly corresponding to Listing 2, with my annotations in the comments. Compiled using arm64 Clang 10.0.0 using -O3 and also -march=armv8.1-a. See on Godbolt Compiler Explorer
If we compare Listing 9 with the ARMv8.0-A version in Listing 7, we can see that Listing 9 is only slightly shorted in terms of total instructions used, but the need for separate ldaxr, stlxr, and clrex instructions has been completely replaced with a single casal instruction.
Interestingly, Listing 9 is now structurally very very similar to it’s x86-64 counterpart in Listing 5.
My guess is that if someone was familiar with x86-64 assembly but had never seen arm64 assembly before, and that person was given Listing 5 and Listing 9 to compare side-by-side, they’d be able to figure out almost immediately what each line in Listing 9 does.
Now let’s see what Listing 3 compiles to using the -march=armv8.1-a flag:
addAtomicFloat(std::atomic<float>&, float):
ldar w9, [x0] // w9 = *arg0 = f0, non-atomically loaded
fmov s1, w9 // s1 = w9 = f0
fadd s2, s1, s0 // s2 = s1 + s0 = (f0 + f1)
mov w8, w9 // w8 = w9 = f0
fmov w10, s2 // w10 = s2 = (f0 + f1)
casal w8, w10, [x0] // atomically read the contents of the address stored
// in x0 (*arg0 = f0) and compare with w8;
// if [x0] == w8:
// atomically set the contents of the
// [x0] to the value in w10
// else:
// w8 = value loaded from [x0]
cmp w8, w9 // compare w8 and w9 and store result in N
b.eq .LBB0_3 // if N==1 { goto .LBB0_3 }
mov w9, w8
.LBB0_2:
fmov s1, w8 // s1 = w8 = value previously loaded from [x0] = f0
fadd s2, s1, s0 // s2 = s1 + s0 = (f0 + f1)
fmov w10, s2 // w10 = s2 = (f0 + f1)
casal w9, w10, [x0] // atomically read the contents of the address stored
// in x0 (*arg0 = f0) and compare with w9;
// if [x0] == w9:
// atomically set the contents of the
// [x0] to the value in w10
// else:
// w9 = value loaded from [x0]
cmp w9, w8 // compare w9 and w8 and store result in N
cset w8, eq // if previous instruction's compare was true,
// set w8 = 1
cmp w8, #1 // compare if w8 == 1 and store result in N
mov w8, w9 // w8 = w9 = value previously loaded from [x0] = f0
b.ne .LBB0_2 // if N==0 { goto .LBB0_2 }
.LBB0_3:
mov v0.16b, v1.16b // return f0 value from ldar
ret
Listing 10: arm64 revision ARMv8.1-A assembly corresponding to Listing 3, with my annotations in the comments. Compiled using arm64 Clang 10.0.0 using -O3 and also -march=armv8.1-a. See on Godbolt Compiler Explorer
Here, the availability of the casal instruction makes a huge difference in the compactness of the output assembly!
Listing 10 is nearly half the length of Listing 8, and more importantly, Listing 10 is also structurally much simpler than Listing 8.
In Listing 10, the compiler still decided to unroll the first iteration of the loop, but the amount of setup and jumping around in between iterations of the loop is significantly reduced, which should make Listing 10 a bit more performant than Listing 8 even before we take into account the performance improvements from using casal.
By the way, remember our discussion of weak versus strong memory models in the previous section?
As you may have noticed, Takua’s implementation of addAtomicFloat() uses std::atomic<T>::compare_exchange_weak() instead of std::atomic<T>::compare_exchange_strong().
The difference between the weak and strong versions of std::atomic<T>::compare_exchange_*() is that the weak version is allowed to sometimes report a failed comparison even if the values are actually equal (that is, the weak version is allowed to spuriously report a false negative), while the strong version guarantees always accurately reporting the outcome of the comparison.
On x86-64, there is no difference between using the weak and strong versions of because x86-64 always provides strong memory ordering (in other words, on x86-64 the weak version is allowed to report a false negative by the spec but never actually does).
However, on arm64, the weak version actually does report false negatives in practice.
The reason I chose to use the weak version is because when the compare-and-exchange is attempted repeatedly in a loop, if the underlying processor actually has weak memory ordering, using the weak version is usually faster than the strong version.
To see why, let’s take a look at the arm64 ARMv8.0-A assembly corresponding to Listing 2, but with std::atomic<T>::compare_exchange_strong() swapped in instead of std::atomic<T>::compare_exchange_weak():
addAtomicFloat(std::atomic<float>&, float):
.LBB0_1:
ldar w8, [x0] // w8 = *arg0 = f0, non-atomically loaded
fmov s1, w8 // s1 = w8 = f0
fadd s2, s1, s0 // s2 = s1 + s0 = (f0 + f1)
fmov w9, s2 // w9 = s2 = (f0 + f1)
.LBB0_2:
ldaxr w10, [x0] // w10 = *arg0 = f0.load(), atomically
// loaded (get exclusive lock on x0), with
// implicit synchronization
cmp w10, w8 // compare non-atomically loaded f0 with atomically
// loaded f0 and store result in N
b.ne .LBB0_4 // if N==0 { goto .LBB0_4 }
stlxr w10, w9, [x0] // if this thread has the exclusive lock,
// { *arg0 = w9 = (f0 + f1), release lock },
// store whether or not succeeded in w10
cbnz w10, .LBB0_2 // if w10 says exclusive lock failed { goto .LBB0_2}
b .LBB0_5 // goto .LBB0_5
.LBB0_4:
clrex // clear this thread's record of exclusive lock
b .LBB0_1 // goto .LBB0_1
.LBB0_5:
mov v0.16b, v1.16b // return f0 value from ldaxr
ret
Listing 11: arm64 revision ARMv8.0-A assembly corresponding to Listing 2 but using std::atomic::compare_exchange_strong() instead of std::atomic::compare_exchange_weak(), with my annotations in the comments. Compiled using arm64 Clang 10.0.0 using -O3 and also -march=armv8.1-a. See on Godbolt Compiler Explorer
If we compare Listing 11 with Listing 7, we can see that just changing the compare and exchange to a strong version instead of a weak version causes a major restructuring of the arm64 assembly and the addition of a bunch more jumps.
In Listing 7, loads from [x0] (corresponding to reads of f0 in the C++ code) happen together at the top of the loop and the loaded values are reused through the rest of the loop.
However, Listing 11 is restructured such that loads from [x0] happen immediately before the instruction that uses the loaded value from [x0] to do a comparison or other operation.
This change means that there is less time for another thread to change the value at [x0] while this thread is still doing stuff.
Interestingly, if we compile using ARMv8.1-A, the availability of single-instruction atomic operations means that just like on x86-64, the difference between the strong and weak versions of the compare and exchange go away and end up compiling to the same arm64 assembly.
At this point in process of porting Takua to arm64, I only had a couple of Raspberry Pis, as Apple Silicon Macs hadn’t even been announced yet.
Unfortunately, the Raspberry Pi 3B’s Cortex-A53-based CPU and the Raspberry Pi 4B’s Cortex-A72-based CPU only implement ARMv8.0-A, which means I couldn’t actually test and compare the versions of the compiled assembly with and without casal.
Fortunately though, we can still compile the code such that if the processor the code is running on implements ARMv8.1-A, the code will use casal and other ARMv8.1-A single-instruction atomic operations, and otherwise if only ARMv8.0-A is implemented, then the code will fall back to using ldaxr, stlxr, and clrex.
We can get the compiler to automatically do the above by using the -moutline-atomics compiler flag, which Richard Henderson of Linaro contributed into GCC 10.1 [Tkachov 2020] and which also recently was added to Clang 12.0.0 in April 2021.
The -moutline-atomics flag tells the compiler to generate a runtime helper function and stub the runtime helper function into the atomic operation call-site instead of directly generating atomic instructions; this helper function then does a runtime check for what atomic instructions are available on the current processor and dispatches to the best possible implementation given the available instructions.
This runtime check is cached to make subsequent calls to the helper function faster.
Using this flag means that if a future Raspberry Pi 5 or something comes out hopefully with support for something newer than ARMv8.0-A, Takua should be able to automatically take advantage of faster single-instruction atomics without me having to reconfigure Takua’s builds per processor.
Performance Testing
So, now that I have Takua up and running on arm64 on Linux, how does it actually perform?
Here are some comparisons, although there are some important caveats.
First, at this stage in the porting process, the only arm64 hardware I had that could actually run reasonably sized scenes on was a Raspberry Pi 4B with 4 GB of memory.
The Raspberry Pi 4B’s CPU is a Broadcom BCM2711, which has 4 Cortex-A72 cores; these cores aren’t exactly fast, and even though the Raspberry Pi 4B came out in 2019, the Cortex-A72 core actually dates back to 2015.
So, for the x86-64 comparison point, I’m using my early 2015 MacBook Air, which also has only 4 GB of memory and has an Intel Core i5-5250U CPU with 2 cores / 4 threads.
Also, as an extremely unfair comparison point, I also ran the comparisons on my workstation, which has 128 GB of memory and dual Intel Xeon E5-2680 CPUs with 8 cores / 16 threads each, for 16 cores / 32 threads in total.
The three scenes I used were the Cornell Box seen in Figure 1, the glass teacup seen in Figure 2, and the bedroom scene from my shadow terminator blog post; these scenes were chosen because they fit in under 4 GB of memory.
All scenes were rendered to 16 samples-per-pixel, because I didn’t want to wait forever.
The Cornell Box and Bedroom scenes are rendered using unidirectional path tracing, while the tea cup scene is rendered using VCM.
The Cornell Box scene is rendered at 1024x1024 resolution, while the Tea Cup and Bedroom scenes are rendered at 1920x1080 resolution.
Here are the results:
CORNELL BOX
1024x1024, PT
Processor:
Wall Time:
Core-Seconds:
Broadcom BCM2711:
440.627 s
approx 1762.51 s
Intel Core i5-5250U:
272.053 s
approx 1088.21 s
Intel Xeon E5-2680 x2:
36.6183 s
approx 1139.79 s
TEA CUP
1920x1080, VCM
Processor:
Wall Time:
Core-Seconds:
Broadcom BCM2711:
2205.072 s
approx 8820.32 s
Intel Core i5-5250U:
2237.136 s
approx 8948.56 s
Intel Xeon E5-2680 x2:
174.872 s
approx 5593.60 s
BEDROOM
1920x1080, PT
Processor:
Wall Time:
Core-Seconds:
Broadcom BCM2711:
5653.66 s
approx 22614.64 s
Intel Core i5-5250U:
4900.54 s
approx 19602.18 s
Intel Xeon E5-2680 x2:
310.35 s
approx 9931.52 s
In the results above, “wall time” refers to how long the render took to complete in real-world time as if measured by a clock on the wall, while “core-seconds” is a measure of how long the render would have taken completely single-threaded.
Both values are separately tracked by the renderer; “wall time” is just a timer that starts when the renderer begins working on its first sample and stops when the very last sample is finished, while “core-seconds” is tracked by using a separate timer per thread and adding up how much time each thread has spent rendering.
The results are interesting!
The Raspberry Pi 4B and 2015 MacBook Air are both just completely outclassed by the dual-Xeon workstation in absolute wall time, but that should come as a surprise to absolutely nobody.
What’s more surprising is that the multiplier by which the dual-Xeon workstation is faster than the Raspberry Pi 4B in wall time is much higher than the multiplier in core-seconds.
For the Cornell Box scene, the dual-Xeon is 12.033x faster than the Raspberry Pi 4B in wall time, but is only 1.546x faster in core-seconds.
For the Tea Cup scene, the dual-Xeon is 12.61x faster than the Raspberry Pi 4B in wall time, but is only 1.577x faster in core-seconds.
For the Bedroom scene, the dual-Xeon is 18.217x faster than the Raspberry Pi 4B in wall time, but is only 2.277x faster in core-seconds.
This difference in wall time multiplier versus core-seconds multiplier indicates that the Raspberry Pi 4B and dual-Xeon workstation are shockingly close in single-threaded performance; the dual-Xeon workstation only has such a crushing lead in wall clock time because it just has way more cores and threads available than the Raspberry Pi 4B.
When we compare the Raspberry Pi 4B to the 2015 MacBook Air, the results are even more interesting.
Between these two machines, the times are actually relatively close; for the Cornell Box and Bedroom scenes, the Raspberry Pi 4B is within striking distance of the 2015 MacBook Air, and for the Tea Cup scene, the Raspberry Pi 4B is actually faster than the 2015 MacBook Air.
The reason the Raspberry Pi 4B is likely faster than the 2014 MacBook Air at the Tea Cup scene is likely because the Tea Cup scene was rendered using VCM; VCM requires the construction of a photon map, and from previous profiling I know that Takua’s photon map builder works better with more actual physical cores.
The Raspberry Pi 4B has four physical cores, whereas the 2014 MacBook Air only has two physical cores and gets to four threads using hyperthreading; my photon map builder doesn’t scale well with hyperthreading.
So, overall, the Raspberry Pi 4B’s arm64 processor intended for phones got handily beat by a dual-Xeon workstation but came very close to a 2015 MacBook Air.
The thing here to remember though, is that the Raspberry Pi 4B’s arm64-based processor has a TDP of just 4 watts!
Contrast with the MacBook Air’s Intel Core i5-5250U, which has a 15 watt TDP, and with the dual Xeon E5-2680 in my workstation, which have a 130 watt TDP each for a combined 260 watt TDP.
For this comparison, I think using the max TDP of each processor is a relatively fair thing to do, since Takua Renderer pushes each CPU to 100% utilization for sustained periods of time.
So, the real story here from an energy perspective is that the Raspberry Pi 4B was between 12 to 18 times slower than the dual-Xeon workstation, but the Raspberry Pi 4B also has a TDP that is 65x lower than the dual-Xeon workstation.
Similarly, the Raspberry Pi 4B nearly matches the 2015 MacBook Air, but with a TDP that is 3.75x lower!
When factoring in energy utilization, the numbers get even more interesting once we look at total energy used across the whole render.
We can get the total energy used for each render by multiplying the wall clock render time with the TDP of each processor (again, we’re assuming 100% processor utilization during each render); this gives us total energy used in watt-seconds, which we divide by 3600 seconds per hour to get watt-hours:
CORNELL BOX
1024x1024, PT
Processor:
Max TDP:
Total Energy Used:
Broadcom BCM2711:
4 W
0.4895 Wh
Intel Core i5-5250U:
15 W
1.1336 Wh
Intel Xeon E5-2680 x2:
260 W
2.6450 Wh
TEA CUP
1920x1080, VCM
Processor:
Max TDP:
Total Energy Used:
Broadcom BCM2711:
4 W
2.4500 Wh
Intel Core i5-5250U:
15 W
9.3214 Wh
Intel Xeon E5-2680 x2:
260 W
12.6297 Wh
BEDROOM
1920x1080, PT
Processor:
Max TDP:
Total Energy Used:
Broadcom BCM2711:
4 W
6.2819 Wh
Intel Core i5-5250U:
15 W
20.4189 Wh
Intel Xeon E5-2680 x2:
260 W
22.4142 Wh
From the numbers above, we can see that even though the Raspberry Pi 4B is a lot slower than the dual-Xeon workstation in wall clock time, the Raspberry Pi 4B absolutely crushes both the 2015 MacBook Air and the dual-Xeon workstation in terms of energy efficiency.
To render the same image, the Raspberry Pi 4B used between approximately 3.5x to 5.5x less energy overall than the dual-Xeon workstation, and used between approximately 2.3x to 3.8x less energy than the 2015 MacBook Air.
It’s also worth noting that the 2015 MacBook Air cost $899 when it first launched (and the processor had a recommended price from Intel of $315), and the dual-Xeon workstation cost… I don’t actually know.
I bought the dual-Xeon workstation used for a pittance when my employer retired it, so I don’t know how much it actually cost new.
But, I do know that the processors in the dual-Xeon had a recommended price from Intel of $1723… each, for a total of $3446 when they were new.
In comparison, the Raspberry Pi 4B with 4 GB of RAM costs about $55 for the entire computer, and the processor cost… well, the actual price for most ARM processors is not ever publicly disclosed, but since a baseline Raspberry Pi 4B costs only $35, the processor can’t have cost more than a few dollars at most, possibly even under a dollar.
I think the main takeaway from these performance comparisons is that even back with 2015 technology, even though most arm64 processors were slower in absolute terms compared to their x86-64 counterparts, the single-threaded performance was already shockingly close, and arm64 energy usage per compute unit and price already were leaving x86-64 in the dust.
Fast forward to the present day in 2021, where we have seen Apple’s arm64-based M1 chip take the absolute performance crown in its category from all x86-64 competitors, at both a lower energy utilization level and a lower price.
The even wilder thing is: the M1 is likely the slowest desktop arm64 chip that Apple will ever ship, and arm64 processors from NVIDIA and Samsung and Qualcomm and Broadcom won’t be far behind in the consumer space while Amazon and Ampere and other companies are also introducing enormous, extremely powerful arm64 chips in the high end server space.
Intel and (especially) AMD aren’t sitting still in the x86-64 space either though.
The next few years are going to be very interesting; no matter what happens, on x86-64 or on arm64, Takua Renderer is now ready to be there!
Conclusion to Part 1
Through the process of porting to arm64 on Linux, I learned a lot about the arm64 architecture and how it differs from x86-64, and I also found a couple of good reminders about topics like memory ordering and how floating point works.
Originally I thought that my post on porting Takua to arm64 would be a nice, short, and fast to write, but instead here we are some 17,000 words later and I have not even gotten to porting Takua to arm64 on macOS and Apple Silicon yet!
So, I think we will stop here for now and save the rest for an upcoming Part 2.
In Part 2, I’ll write about the process to port to arm64, about how to create Universal Binaries, and examine Apple’s Rosetta 2 system for running x86-64 binaries on arm64.
Also, in Part 2 we’ll examine how Embree works on arm64 and compare arm64’s NEON vector extensions with x86-64’s SSE vector extensions, and we’ll finish with some additional miscellaneous differences between x86-64 and arm64 that need to be considered when writing C++ code for both architectures.
Acknowledgements
Thanks so much to Mark Lee and Wei-Feng Wayne Huang for puzzling through some of the std::compare_exchange_weak() stuff with me.
Thanks a ton to Josh Filstrup for proofreading and giving feedback and suggestions on this post pre-release!
Josh was the one who told me about the Herbie tool mentioned in the floating point section, and he made an interesting suggestion about using e-graph analysis to better understand floating point behavior.
Also Josh pointed out SuperH as an example of a variable width RISC architecture, which of course he would because he knows all there is to know about the Sega Dreamcast.
Finally, thanks to my wife, Harmony Li, for being patient with me while I wrote up this monster of a blog post and for also puzzling through some of the technical details with me.
References
Pontus Andersson, Jim Nilsson, Tomas Akenine-Möller, Magnus Oskarsson, Kalle Åström, and Mark D. Fairchild. 2020. FLIP: A Difference Evaluator for Alternating Images. Proc. of the ACM on Computer Graphics and Interactive Techniques (Proc. of High Performance Graphics) 3, 2 (Jul. 2020), Article 15.