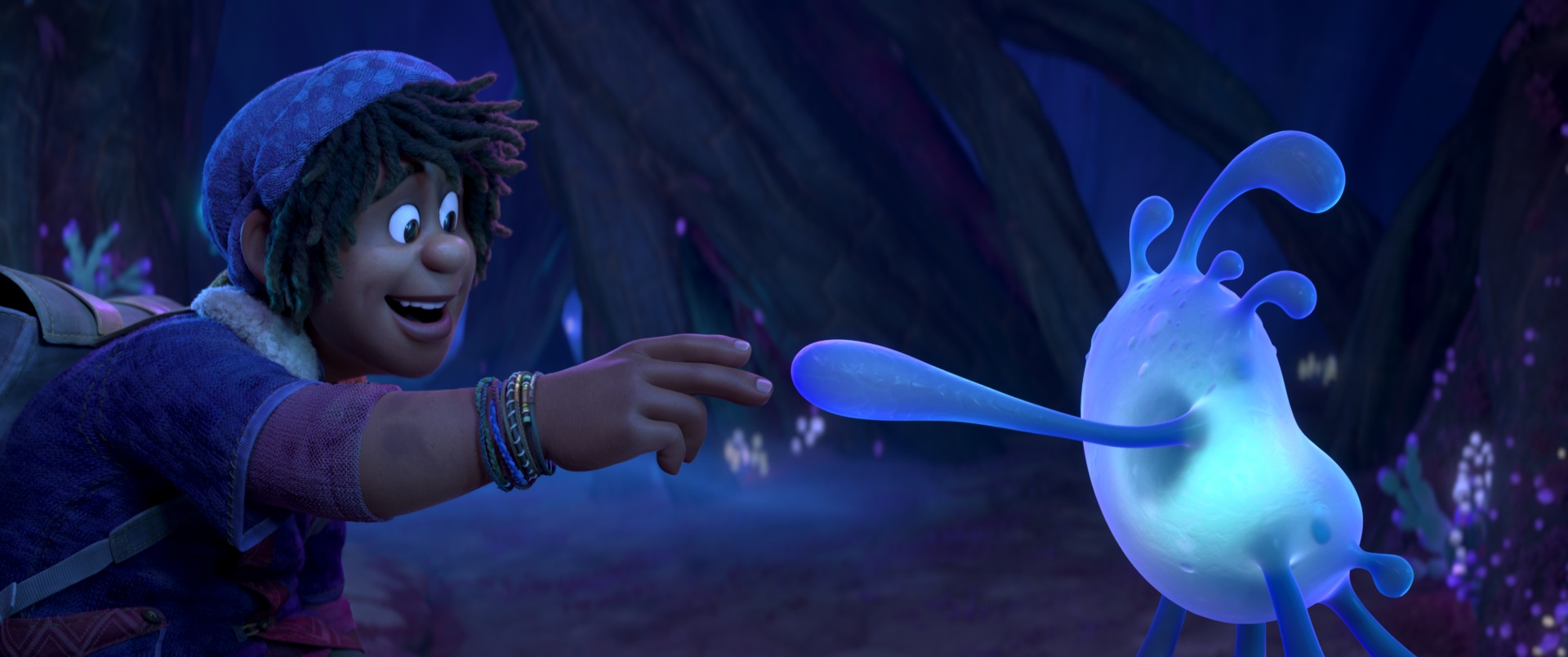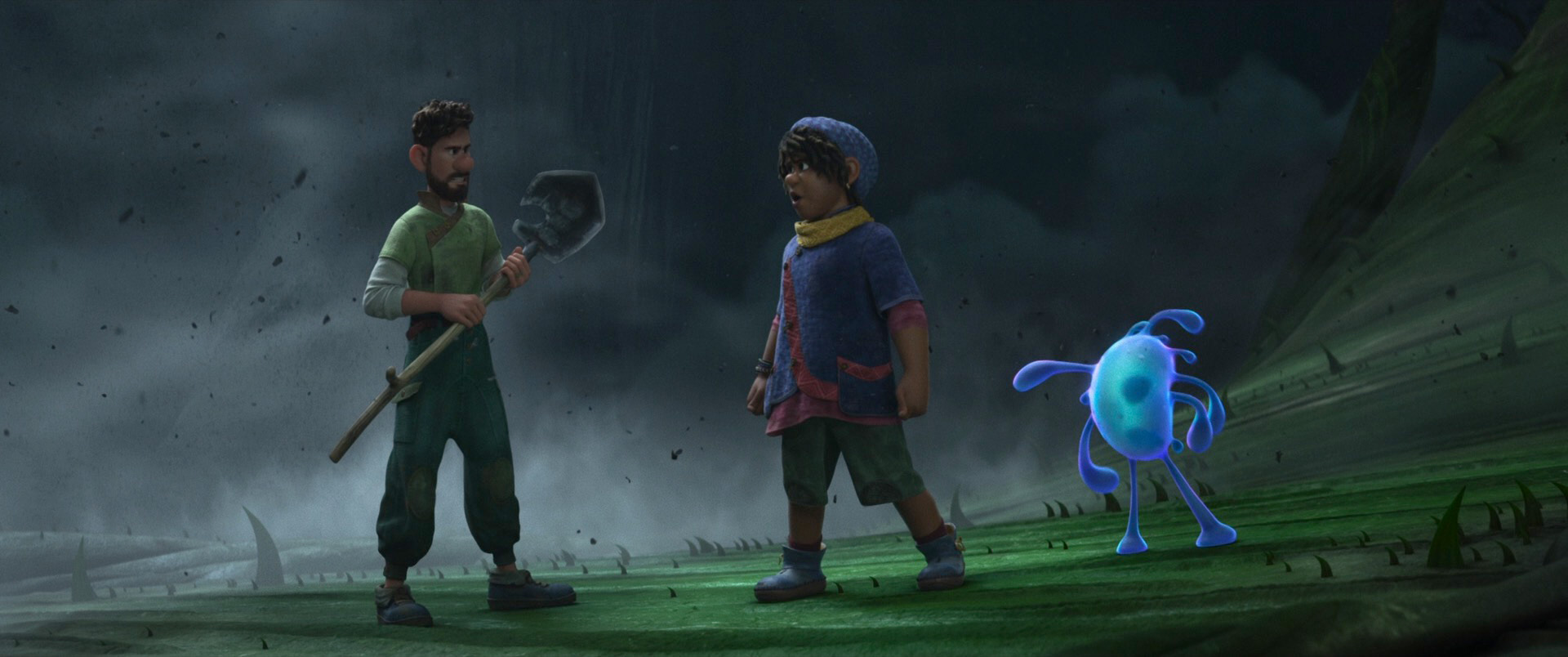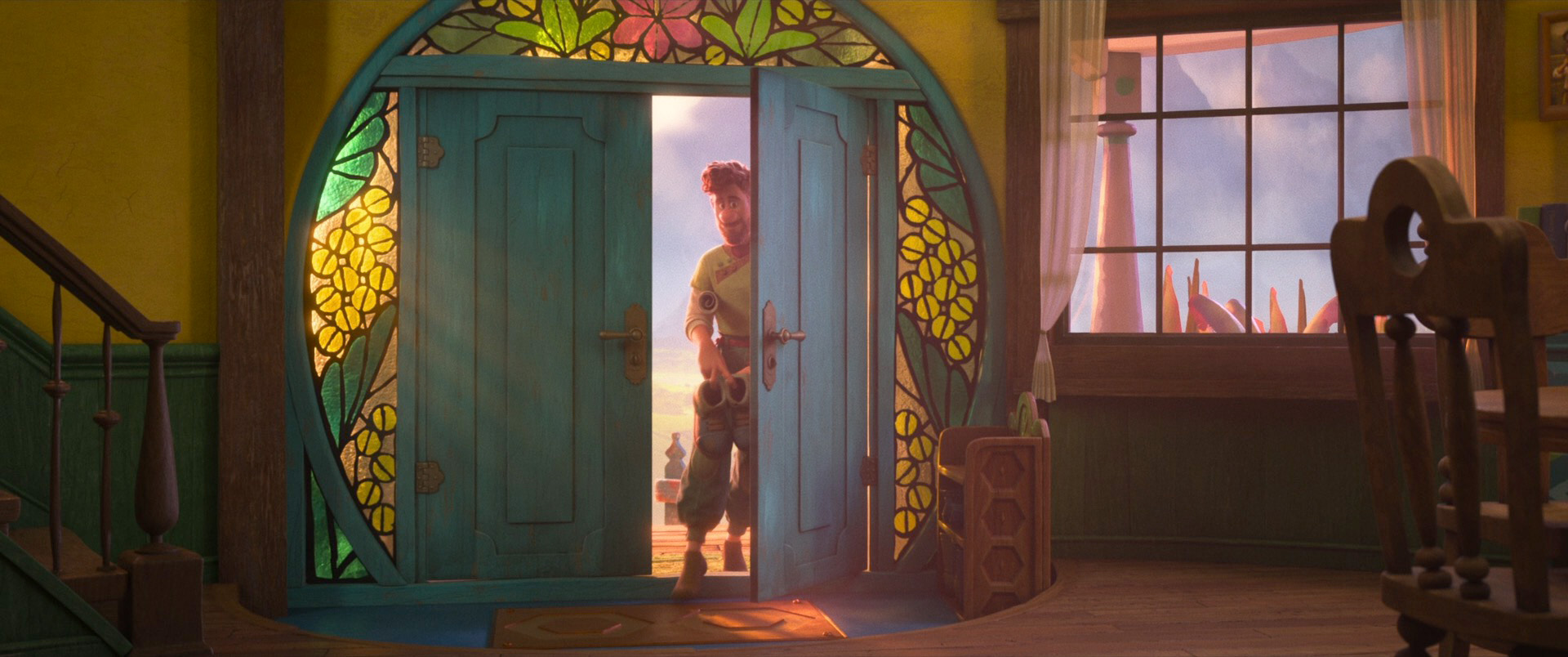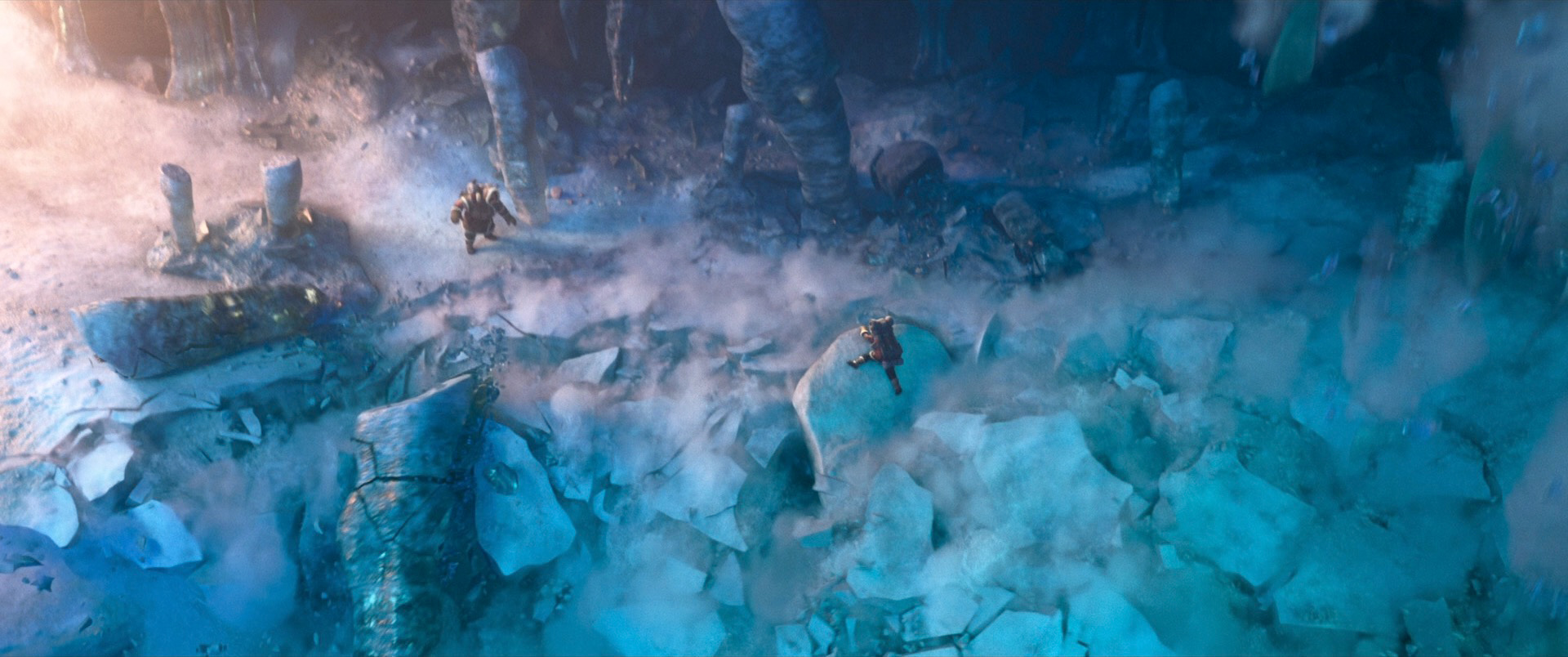Wish
Disney Animation’s fall 2023 release is Wish, which is the studio’s 62nd animated feature and also the studio’s film celebrating the 100th anniversary of Disney Animation and The Walt Disney Company. Wish is a brand new story but is also steeped in the past century of Disney storytelling; while Asha and Star and Valentino’s adventure is a new musical story, the themes and setting Wish draws upon are timeless and classic. As part of this theme of modern Disney with throwback elements, Wish also has a unique beautiful visual style that combines the latest of our computer graphics animation with a classic watercolor style. Creating this style presented an interesting set of new challenges for our artists, TDs, engineers, and for Disney’s Hyperion Renderer.

At Disney Animation, every one of our films is a new opportunity for us to push our filmmaking art and technology forward. On most films this advancement takes place across many different aspects of the film, but on Wish, there is one obvious challenge that stood out above everything else: the film’s visual style. Of course we still made large improvements in other areas, such as major pipeline optimizations [Li et al. 2024a], but on Wish a large proportion of technology development was focused on achieving the target visual style. One could be forgiven for thinking that stylization is mostly a rendering problem, but on Wish it really was a challenge that reached into every department and every corner or our production process. Stylization on Wish meant stylization in modeling, lookdev, animation, effects, lighting, everything else in between, and even new pipeline challenges!
The decision to give Wish a unique style came from pretty much the very beginning of the project; the studio wanted to do something special for the 100th anniversary film to tie together our modern way of making animated films with the studio’s rich hand-drawn heritage. The look of Wish is especially influenced by early 20th century Disney traditional watercolor animation, with Snow White and the Seven Dwarfs (1937) and Sleeping Beauty (1959) being the largest guideposts. This influence extends all the way to the very shape of the film, so to speak- Wish is the first CG film that Disney Animation has made in the ultrawide 2.55:1 Cinemascope-style aspect ratio, matching the aspect ratio that was used on Sleeping Beauty and Lady and the Tramp (1955). This aspect ratio choice meant that stylization on Wish even impacted layout, since they had to think about how to frame for such an ultrawide image!
Disney Animation has a long history of stylizing 3D CG to resemble and fit in with hand-drawn animation, going all the way back to the studio’s traditional hand-drawn era [Meier 1996, Daniels 1999, Tamstorf et al. 2001, Odermatt and Springfield 2002, Teece 2003]. In the 3D CG era, Disney Animation has continually experimented with stylizing CG as well with a number of different approaches. Paperman focused on integrating 2D linework with 3D rendered characters [Kahrs et al. 2012 ,Whited et al. 2012], while Feast experimented with driving 2D lighting entirely in compositing on top of flat unlit/unshaded 3D renders [Osborne and Staub 2014]. The studio’s recent Short Circuit experimental shorts program had many shorts that experimented with a variety of different stylized looks, ranging from Chinese ink brush watercolors to graphic 2D illustrations to stop motion and wood carved looks [Newfield and Staub 2020]. Disney Research has also worked closely with Disney Animation in the past decade plus to develop various experimental stylization techniques [Schmid et al. 2011, Sýkora et al. 2014]. Both Strange World and Raya and the Last Dragon had small amounts of stylized sequences as well, with Strange World doing a 1950s pulp scifi comic book look and Raya and the Last Dragon doing a more graphic digital mixed media sort of look. Most recently, the short Far From the Tree utilized a look with cel-shaded characters on watercolor backgrounds. All of these were animated using our standard 3D pipeline, with much of the look being built using a combination of render passes from the renderer (Hyperion for everything except Paperman, which preceded Hyperion’s existence by a few years), various tricks in lighting, and a lot of work in compositing; how much of each was used varied widely per show and per target style.
Wish builds upon all of these predecessors. Wish’s stylization system is a vastly expanded version of what was used on Far From the Tree, which in turn was built on top of everything that was developed for Short Circuit, which in turn drew upon lessons from both Feast and Paperman. One of the biggest challenges came from having to scale up a stylization pipeline from a short film to a full feature length project, while also trying to hit a new target style. Early tests on the show were able to reproduce in CG the target visdev paintings essentially exactly, but through entirely ad-hoc and mostly manual approaches, which we then had to systematically take apart and figure out how to apply to the whole movie. My wife, Harmony Li, was an Associate Technical Supervisor on the show and (among a ton of other things) oversaw the development of the entire technical backend that was built out to support stylization on Wish [Li et al. 2024b]; as a member of the rendering team, I got to work with her on this, which was great fun! Meanwhile, much of the development for the actual techniques used was led primarily by lighting and lookdev artists.
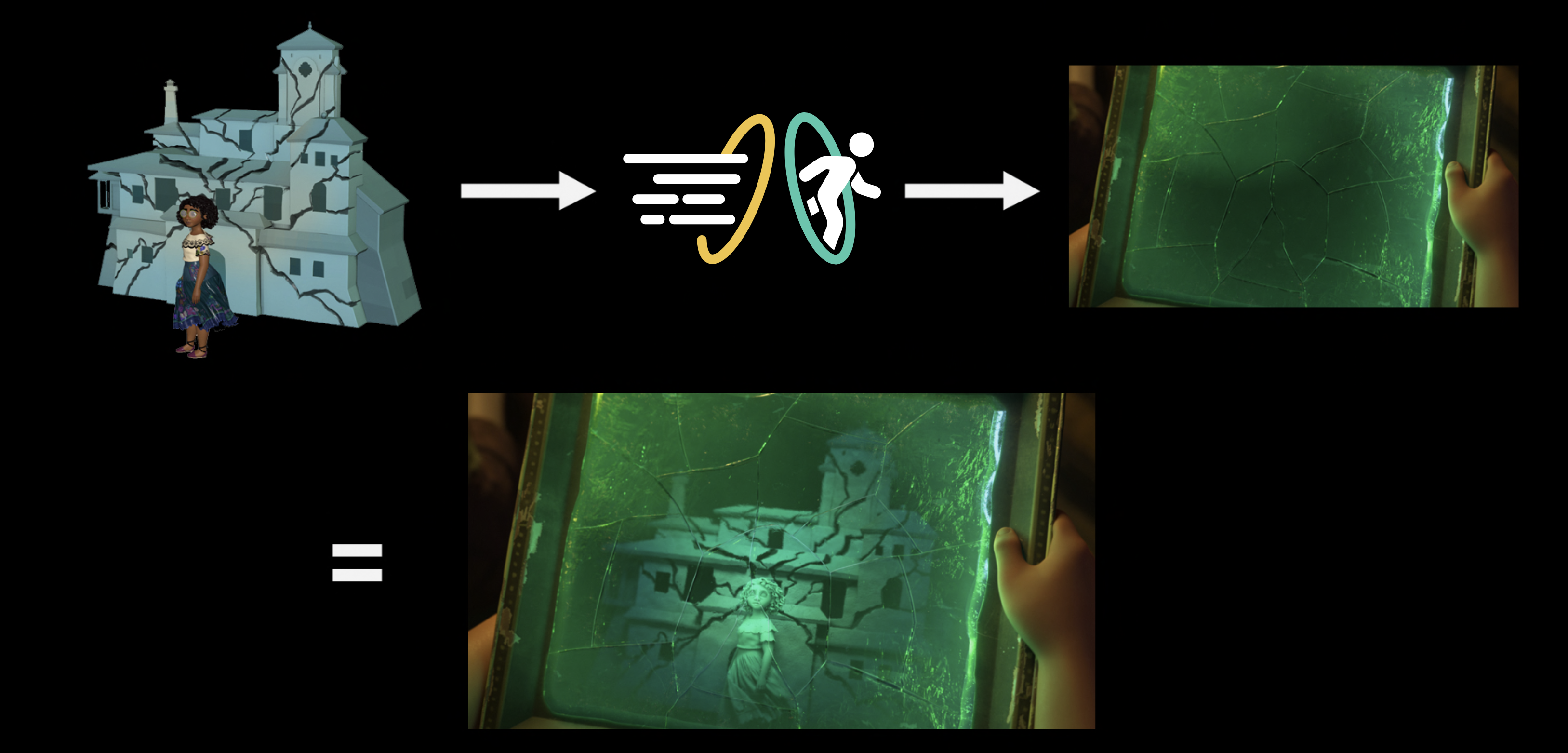
An early breakthrough in achieving Wish’s style was finding that combining Kuwahara filters1 [Kuwahara et al. 1976] with linework generated from the renderer created a convincing starting point for a line-on-watercolor look that could use the renderer’s physical lighting as a starting point, instead of needing to construct stylized lighting entirely from scratch in comp on top of flat-shaded unlit renders. To help really tie together the watercolor look, early tests put the entire image on a watercolor paper texture background, but once we tested the watercolor paper texture background in motion, some issues became apparent. With just a static watercolor paper texture background, the illusion of motion broke as animation looked like it was “swimming” through the texture, but simply texturing everything with watercolor textures in 3D space looked downright bizarre since it looked less like the frame was a watercolor painting and more like all of the characters and the environment were made out of paper. To solve this problem, the Hyperion team invented a new dynamic screen space texture technique [Burley et al. 2024] where the renderer would project screen space textures onto 3D surfaces while tracking motion vectors. The result is that Wish’s watercolor backgrounds look like just a flat sheet of watercolor paper when still, but under motion convincingly move with the characters while neither looking like they’re actually in 3D space nor looking disconnected from motion.
One interesting question I worked on for Wish was making Hyperion robustly handle shading normals that are really dramatically disconnected from the underlying “physically correct” geometric normal. Extreme bending of normals was used extensively on Wish to simplify shapes and art-direct lighting detail and shadows. In a normal physically based path traced render, shading normals coming from bump mapping and normal mapping usually have at least some relationship with the underlying true geometric normal, meaning that the ways shading normals modify light transport are relatively constrained to a plausible range. However, on Wish, extreme shading normals were used for things like simplifying the lighting on an entire complex tree canopy to match what the lighting would be on a simple sphere. Making Hyperion handle these cases both from an authoring perspective and making Hyperion’s light transport robust against these cases took some work!
There were actually also some more traditional physically based rendering problems to solve on Wish too, which one might not necessarily expect for such a stylized film. For some of Magnifico’s magic, the art-direction called for a sort of prismatic look where white light would get split into different colors. We decided to try to achieve this effect through physically based shading, since the starting point for Wish’s entire stylization pipeline was renders with physical lighting in order to provide consistency. To achieve this effect through physically based shading, I extended the Disney BSDF with spectral dispersion support (retrofitting a spectral effect into a non-spectral renderer was a fun challenge worth discussing on its own someday). Once our lookdev artists had access to dispersion within the Disney BSDF, it was fun seeing all of the other places where they started sprinkling the effect in, such as in various glass objects.
Stylization on Wish didn’t just mean new renderer effects and lighting and compositing work; in order to make characters read correctly in a watercolor look, stylization had to be incorporated into all of the characters at a geometric and design level as well, and had to be incorporated into animation and simulation. As an example: a core story device in Wish is the collective wishes of Rosas, which take the form of orbs containing entire small worlds set inside of swirling volumetrics. Creating these wishes required clever pipeline solutions to embed entire stylized animated scenes inside of the orbs in 3D space, which was used instead of a usual compositing-based insert-shot workflow or the teleport-based solution [Butler et al. 2022] used on Encanto; this approach was taken in order to provide animators with the ability to sync and see fully combined shots interactively and to simplify the rendering setup needed for stylization in lighting and compositing [Karanam et al. 2024]. On top of creating the individual wishes, huge numbers of wishes then had to be choreographed into tight, closely synchronized formations to meet the art-direction and shape language of the songs they were a part of, which required developing new crowd rigs and animation controls. The rendering aspect of the wishes was in a lot of ways actually the easy part! Each wish was also an internally emissive object, so when thousands of wishes are massed together in key sequences in the movie, we initially had some concerns about efficiently rendering all of the wishes, but our long-standing cache points many-light selection strategy [Li et al. 2024c] proved to be more than capable for the task.
Another example of stylization far upstream of lighting is in the project’s entire approach to character stylization. Character hair and fur grooms required a different approach from our usual process; normally in more photoreal Disney Animation films, hair and fur grooms are built to be highly detailed to support the rich detailed look of the film, but Wish’s watercolor style meant using a more simplified and graphic shape language across the board, where detail is traded off for a stronger focus on silhouette and overall massing. Hair and fur grooms had to be adjusted to match, and hair and fur simulation had to be adjusted to keep art-directed shapes intact instead of operating on a more individual strand-based level [Kaur and Stratton 2024]. Asha’s braids, with their North African inspired long box braids, required additional attention to create and simulate [Kaur et al. 2024]. The braids themselves were already a major technical challenge; even using our state-of-the-art in-house grooming system Tonic [Simmons and Whited 2014], the braids still required a final groom two orders of magnitude more complex than our average groom. Once Asha’s groom was figured out, her hair then had to also be put through the same stylized simulation setup mentioned earlier, with extensive 2D drawovers being used to art-direct simulations. Character animation then also had to take into account the fact that Wish does not have motion blur and how that impacts how viewers perceive character performances.
Speaking of 2D drawovers, one particularly interesting use of 2D drawings to art-direct stylization on Wish is in Magnifico’s magic and in various effects like flames and torches. Normal volumetric effects created from simulations tend to be highly physical and detailed, but Wish’s style called for these effects to harken back to the much more graphic shape language of magic effects from Disney Animation’s hand-drawn era. To do this, our effects artists built on top of the neural volume style transfer work from Raya and the Last Dragon [Navarro and Rice 2021] and Strange World [Navarro 2023] to develop a new system where effects animation would begin with hand-drawn 2D elements, which were then projected and extruded into the 3D space to provide a guide for neural volume style transfer on top of volume simulations [Tollec and Navarro 2024]. The result is that Wish’s volumetric effects combine the movement and interactions of physical simulations while retaining the shape and style of traditional hand-drawn effects.
Everything I’ve written about here is just what I was familiar with on this film; vastly more work went into every single frame of Wish than even I know. The final look of Wish is something that I think really is unique and beautiful. Wish’s 3D watercolor look speaks to the entire history of Disney Animation and simultaneously roots itself in the studio’s rich traditional hand-drawn legacy while also exemplifying the studio’s long history of innovating and driving filmmaking craft forward. Walt Disney never stopped seeking to innovate in animation, and 100 years after he founded the studio, the animation studio that carries his name today continues to embody that same bold spirit on every new film. As someone who’s a lifelong fan and student of animation, I feel incredibly humbled and fortunate to get to contribute towards that legacy every day.
Below are some frames from Wish, pulled from the Blu-ray and presented in no particular order. As always, I’d highly recommend seeing Wish on the biggest screen you can find!








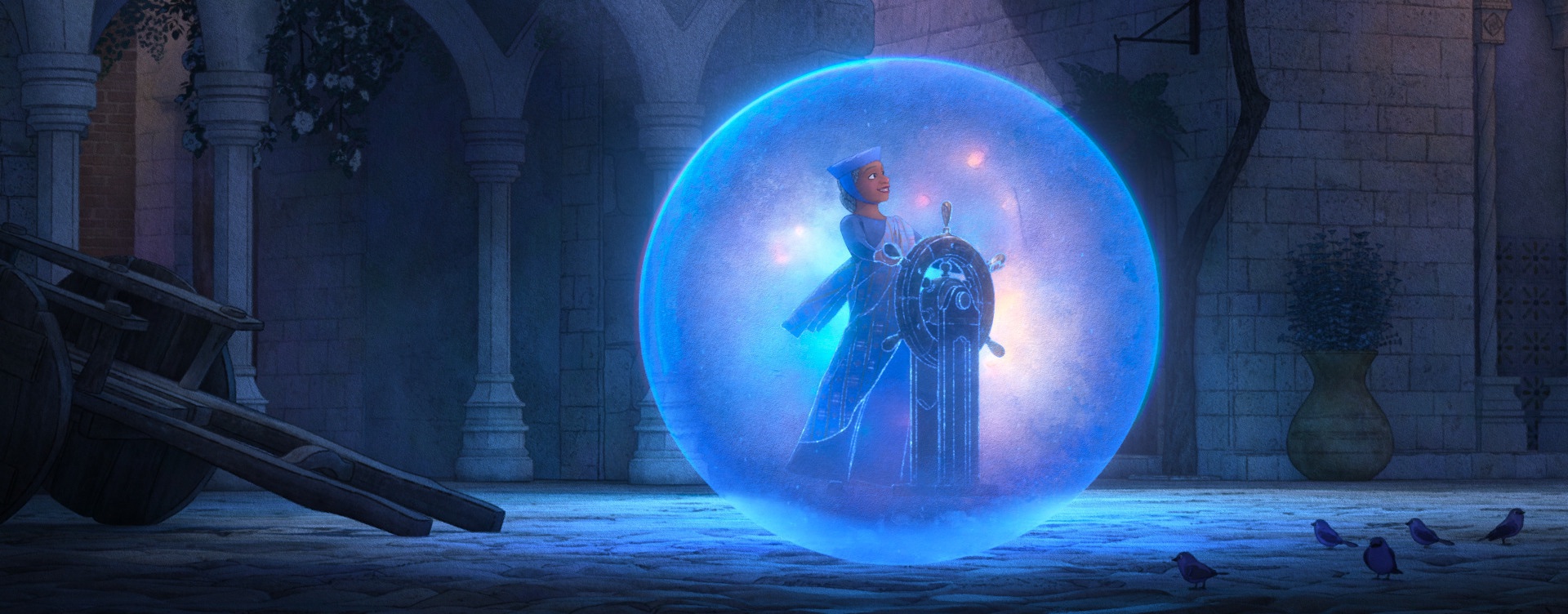




























































































Here are two credits frames from Wish; the first is the fancy hero-credit card for my wife Harmony Li and her fellow Associate Technical Supervisors, and the second is for the Hyperion team, along with several of the Hyperion’s sister technology teams that all support lighting and lookdev. Also, Wish has a lovely post-credits scene that I’d encourage sticking around for!


All images in this post are courtesy of and the property of Walt Disney Animation Studios.
References
Brent Burley, Brian Green, and Daniel Teece. 2024. Dynamic Screen Space Textures for Coherent Stylization. In ACM SIGGRAPH 2024 Talks. Article 50.
Corey Butler, Brent Burley, Wei-Feng Wayne Huang, Yining Karl Li, and Benjamin Huang. 2022. “Encanto” - Let’s Talk About Bruno’s Visions. In ACM SIGGRAPH 2022 Talks. Article 8.
Eric Daniels. 1999. Deep Canvas in Disney’s Tarzan. In ACM SIGGRAPH 1999 Sketches & Applications. 200.
Avneet Kaur, Jennifer Stratton, David Hutchins, and Nikki Mull. 2024. Art-Directing Asha’s Braids in Disney’s Wish. In ACM SIGGRAPH 2024 Talks. Article 4.
Avneet Kaur and Jennifer Stratton. 2024. Character Stylization in Disney’s Wish. In ACM SIGGRAPH 2024 Talks. Article 5.
John Kahrs, Patrick Osborne, Amol Sathe, Jeff Turley, Brian Whited, and Darrin Butters. 2012. The Art and Science Behind Walt Disney Animation Studios’ “Paperman”. In ACM SIGGRAPH 2012 Production Sessions.
Neelima Karanam, Joel Einhorn, Emily Vo, and Harmony M. Li. 2024. Creating the Wishes of Rosas. In ACM SIGGRAPH 2024 Talks. Article 6.
Michiyoshi Kuwahara, Kozaburo Hachimura, Shigeru Eiho, and Masato Kinoshita. 1976. Processing of RI-Angiocardiographic Images. In Digital Processing of Biomedical Images. 187-202.
Harmony M. Li, George Rieckenberg, Neelima Karanam, Emily Vo, and Kelsey Hurley. 2024a. Optimizing Assets for Authoring and Consumption in USD. In ACM SIGGRAPH 2024 Talks. Article 30.
Harmony M. Li, Angela McBride, Sari Rodrig, and Gregory Culp. 2024b. A Pipeline for Effective and Extensible Stylization. In ACM SIGGRAPH 2024 Talks. Article 51.
Yining Karl Li, Charlotte Zhu, Gregory Nichols, Peter Kutz, Wei-Feng Wayne Huang, David Adler, Brent Burley, and Daniel Teece. 2024c. Cache Points for Production-Scale Occlusion-Aware Many-Lights Sampling and Volumetric Scattering. In Proc. of Digital Production Symposium (DigiPro 2024). Article 6.
Barbara J. Meier. 1996. Painterly Rendering for Animation. In SIGGRAPH 1996: Proceedings of the 23rd Annual Conference on Computer Graphics and Interactive Techniques. 477-484.
Mike Navarro and Jacob Rice. 2021. Stylizing Volumes with Neural Networks. In ACM SIGGRAPH 2021 Talks. Article 54.
Mike Navarro. 2023. Diving Deeper Into Volume Style Transfer. In ACM SIGGRAPH 2023 Talks. Article 39.
Jennifer Newfield and Josh Staub. 2020. How Short Circuit Experiments: Experimental Filmmaking at Walt Disney Animation Studios. In ACM SIGGRAPH 2020 Talks. Article 72.
Kyle Odermatt and Chris Springfield. 2002. Creating 3D Painterly Environments for Disney’s “Treasure Planet”. In ACM SIGGRAPH 2002 Sketches & Applications. 160.
Patrick Osborne and Josh Staub. 2014. Feast – A Look at Walt Disney Animation Studios’ Newest Short. In ACM SIGGRAPH 2014 Production Sessions.
Johannes Schmid, Martin Sebastian Senn, Markus Gross, and Robert W. Sumner. 2011. OverCoat: An Implicit Canvas for 3D Painting. ACM Transactions on Graphics (Proc. of SIGGRAPH) 30, 4 (Jul. 2011), Article 28.
Maryann Simmons and Brian Whited. 2014. Disney’s Hair Pipeline: Crafting Hair Styles From Design to Motion. In Eurographics 2014 Industrial Presentation.
Daniel Sýkora, Ladislav Kavan, Martin Čadik, Ondrej Jamriška, Alec Jacobson, Brian Whited, Maryann Simmons, and Olga Sorkine-Hornung. 2014. Ink-and-Ray: Bas-relief Meshes for Adding Global Illumination Effects to Hand-Drawn Characters. ACM Transactions on Graphics 33, 2 (Apr. 2016), Article 16.
Rasmus Tamstorf, Ramón Montoya-Vozmediano, Daniel Teece, and Patrick Dalton. 2001. Hybrid Ink-Line Rendering in a Production Environment. In ACM SIGGRAPH 2001 Sketches & Applications. 201.
Daniel Teece. 2003. Sable - a Painterly Renderer for Film Animation. In ACM SIGGRAPH 2003 Sketches & Applications.
Marie Tollec and Mike Navarro. 2024. Making Magic with 3D Volume Style Transfer. In ACM SIGGRAPH 2024 Talks. Article 48.
Brian Whited, Eric Daniels, Michael Kaschalk, Patrick Osborne, and Kyle Odermatt. 2012. Computer-Assisted Animation of Line and Paint in Disney’s Paperman. In ACM SIGGRAPH 2012 Talks. Article 19.
Footnotes
1 I recently learned that the Kuwahara filter originated from completely outside of graphics; it was originally invented at Kyoto University’s medical school and at Shiga University of Medical Science for medical imaging purposes. Specifically, it was invented for reducing noise in radioisotopic heart scans without blurring sharp features, and much later graphics people realized it made for a great edge-preserving blur for painting-like effects. I love when graphics intersects with other fields to produce interesting results! keyboard_return